

Von Null nach SNMP
Ich bin auf der Suche nach einem Monitoring Plugin für den Spam- und Virenfilter für Mails rspamd. Das ist ziemlich ernüchtern da ich außer dem check_tcp auf die verwendeten Ports nichts gefunden habe. (mehr …)
Ich bin auf der Suche nach einem Monitoring Plugin für den Spam- und Virenfilter für Mails rspamd. Das ist ziemlich ernüchtern da ich außer dem check_tcp auf die verwendeten Ports nichts gefunden habe. (mehr …)

Monitoring kann spannende Dinge überwachen. Funktioniert richtig toll solange das Ziel direkt via Netzwerk vom Monitorring aus erreichbar ist. Ein SMTP Server lauscht üblicherweise auf Port 25 und dort geht - oh Wunder - doch tatsächlich ein SMTP-Server ran. Lässt sich super mit einem Check prüfen welcher SMTP spricht. Nur was ist wenn es keinen Netzwerkdienst zu der überwachenden Komponente gibt? Solche Dinge wie der Füllstand der Festplatte, die Auslastung der CPU? Ein Agent muss auf das Zielsystem. Bleibt die Frage nach dem welchem. Ein kurzer Überblick der Möglichkeiten.
Wer ohnehin Icinga2 nutzt kann auch gleich den Icinga2 Agent nutzen. Der ist klein, schlank und sicher. Dazu ist er sauber in Icinga integriert. Klar, ist ja schließlich Icinga selbst. Hauptnachteil für mich: Der bläht die Zonenconfig immer so ungemein auf. Für einzelne Rechner wo man überwachen will gleich den großen Aufwand mit Zonen- und Endpoint-Config wagen? Kann man machen. Für alle ohne Icinga: ganz klar, hier muss was anderes her. Oder wechselt zu Icinga. Kann ich wärmstens empfehlen 😉
Lange Zeit erstes Mittel der Wahl: NRPE, der Nagios Remote Plugin Executor (https://github.com/NagiosEnterprises/nrpe). Seit 2017 keine Änderung mehr. Wozu auch? Solange es funktioniert ist ja alles gut. Ja, NRPE ist simpel und einfach. Und da liegt vermutlich das Problem. Verschlüsselung gibt es, jedoch keine Authentifizierung. Lediglich das frei schalten von IP-Adressen welche Anfragen stellen dürfen. Dazu noch die tolle Problematik rund um dont_blame_nrpe. Jeder der das Konstrukt kennt weiß was ich meine. Ansonsten einfach mal nach dem Schalter in der Dokumentation suchen. Viel Spaß beim lesen 😉
Zusammengefasst: Kann man machen. Im abgeschlossenen Netzwerk hinter einer Firewall sollte Verschlüsselung und IP Filter reichen. Das Ding ist klein und schlank, die Problematik rund um dont_blame_nrpe haben genau genommen alle Remote Agent Lösungen. Dumm nur, dass bei aktuellen Distributionen wie z.B. SLES 15.1 der Trend dazu geht NRPE nicht mehr mit auszuliefern. Zu lange keine Änderungen an den Paketen heißt es in der Begründung. Dem Trend werden vermutlich weitere Distributionen folgen bzw. sind schon gefolgt. Als NRPE Nutzer sollte man wohl zumindest offen für anderes sein - jenachdem was die Zukunft einem zu bieten hat.
Oder nur by_ssh wie es innerhalb von Icinga heißt. Jemand schon mal bei NRPE das Problem gehabt, dass der Ausgabe Text gekürzt wurde? Weil die maximale Größe für die Ausgaben seitens Quellcode auf 1024 Zeichen beschränkt wurde? Und wie gelöst? By_ssh? Willkommen im Verein 😉
Oder auch anders ausgedrückt: Welches Linux-System hat keinen ssh Server am laufen? Wenn es im Netz steht und man Monitoring darauf ansetzt dürfte es das so gut wie nie geben. Die Problematik der NRPE Installation ist weg, die Sicherheit ist hoch: Verschlüsselung und Authentifizierung ist bei ssh einfach super gelöst. Die dont_blame-Problematik ist hier sinngemäß die Gleiche: Wenn man erlaubt Argumente zu übergeben könnte jemand Blödsinn machen. Könnte. Heißt ja nicht gleich "muss". Oder einfach keine Argumente zu lassen. Problem der Eventualität gelöst. Wo nichts ist kann auch niemand. Klingt super, oder? Naja, ein Problem fällt mir spontan dazu schon ein. Spaßverderber, ich weiß: Ich brauche einen Benutzer der sich via ssh anmelden kann.
Ok, das ist ja jetzt nicht so das Thema. Das Thema ist eher: Checks sind meistens irgendwelche Skripte, der Benutzer fürs Monitoring braucht somit eine Login-Shell. Der Benutzer kann sich also am System anmelden und Dinge tun die er aus Sicht des Monitoring gar nicht braucht. Wenn jetzt irgendjemand das Monitroing-System knackt und dort die Zugangsdaten fürs ssh ausliest oder den hinterlegten key entsprechend weiter verwendet... Ihr seht schon auf was ich raus will. Der Benutzer braucht also so irgendwas wie chroot mit nur den Checks und Bibliotheken drin die er braucht. Und vermutlich noch das proc-System weil da heraus solche Dinge wie Festplattenbelegung usw. heraus gelesen werden. Und was sonst noch alles so fehlt. Puh, ganz schön aufwendig.
Geht auch etwas anders: Für jeden Check einen eigenen Benutzer anlegen und dem via sshd-Config als auszuführendes Programm den entsprechenden Check hinterlegen. Oder die Login-Shell bei dem Benutzer auf den Check ändern. Irgendwas, was keine Anmeldung mehr in Richtung Shell mit der Möglichkeit der eigenen Befehlseingabe erlaubt.
Machbar also. Mit Aufwand. Ein Hoch auf Orchestrierungstools wie ansible, puppet, chef oder wie die alle auch heißen mögen.
Ganz anderer Ansatz: SNMP kennt man. Drucker, Netzwerkkomponenten, diverse Appliances. Die alle haben SNMP drauf und das funktioniert doch super. Ok, in Version 2 mit Community-String ist die Sicherheit so naja. Aber spätestens mit v3 wo Authentifizierung und Verschlüsselung gefordert werden kann ist doch alles wunderbar. Und wenn dann der Monitoringbenutzer im SNMP-Baum unter seiner Kennung nur das findet was er fürs Monitoring braucht ist doch alles perfekt. Bleibt die Frage was mit den eigentlichen Checks fürs Monitoring ist.
Also der Reihe mal nach durchgehen: SNMP ist unter Linux rasch installiert. Von Haus aus gibt es bei Icinga bereits die Checks welche via SNMP CPU, RAM, Prozesse, Plattenplatz usw. auswerten können. Grobe Sicht auf das was die Hardware betrifft: Läuft. Und die speziellen Checks welche man ggf. sogar noch selbst programmiert hat? Ja, die laufen auch. Einfach in die Config mit aufnehmen, im Internet nach check_by_snmp suchen und wie analog zu NRPE oder by_ssh verwenden. Läuft ebenfalls (Links finden sich weiter unten).
Ok, braucht man einen snmpd-Dienst. Einen extra Dienst brauchst bei NRPE aber ebenfalls. Die Checks muss man in der Config definieren. Musst bei NRPE ebenfalls und wenn by_ssh "richtig" machen willst ja auch. Von daher tut das eigentlich nicht weh. Ein weiterer Vorteil gefällig? Systeminventarisierung welche via SNMP Systeme ermittelt? Klar, das kannst jetzt ebenfalls machen. Ein spezielles Überwachungstool welches zusätzlich zum Monitoring läuft und ebenfalls SNMP kann? Na logisch doch, kein Problem. Und ich kenn sogar noch eine GroupWare Lösung welche via Webfrontend überwacht werden kann. Oder via AgentX Schnittstelle den lokal installierten SNMP erweitert. Somit ohne speziellen Checks am Monitoring dran. Das macht Laune, weil das funktioniert mit jeglichem Monitoring welches SNMP kann.
SNMP ist viel spannender als man zunächst ggf. vermutet hätte. Jeder der das bisher noch nicht nutzt sollte es zumindest mal anschauen. Es lohnt sich!
Hier gibt es ebenfalls SNMP. Was der so alles kann und ob bzw. wie man den erweitert weiß ich nicht wirklich. Gerne Kommentare dazu her!
Ich selbst nutze dafür bisher eigentlich immer diesen Weg: https://icinga.com/docs/icinga2/latest/doc/07-agent-based-monitoring/#nsclient-on-windows. Dank Icinga Agent ist die Übertragung gesichert und man kann über nscp ohne großen Aufwand alles mögliche Rund um Windows abfragen.
Ich nehme inzwischen ganz gerne um so etwas zu testen einen Docker Container. Hat den Vorteil, dass ich den Dienst in einem Container starten und falls ich den nicht mehr brauche einfach löschen kann. Ebenso unkompliziert ist es kurzerhand einen zweiten Dienst mit anderer Konifg parallel zu starten falls man was probieren möchte. Geht aber auch ohne Docker. Für alle mit Docker bzw. Docker interessierten füge ich hier mal meine docker-compose und dockerbuild Datei an:

Ginge auch ohne compose - zumal ich mit nur einem Container ausgekommen bin 😉
#
# Gehirn-Mag.Net snmpd
#
version: '3'
services:
snmpd:
build:
context: .
dockerfile: snmpd.Dockerfile
ports:
- "127.0.0.1:161:161/udp"
volumes:
- ./volumes/etc_snmp/:/etc/snmp/
Mein Docker-Container basiert auf Ubuntu 18.04. Sollte ein Proxy notwendig sein um das Internet zu erreichen einfach die beiden Proxy-Zeilen entsprechend anpassen.
FROM ubuntu:18.04
# Notwendige Software installieren
#ENV http_proxy=http://xxxx:xxxx@10.1.1.1:3128/
#ENV https_proxy=http://xxxx:xxxx@10.1.1.1:3128/
RUN apt-get update && apt-get install -y snmpd snmp-mibs-downloader snmp openssl monitoring-plugins git wget
RUN git clone https://github.com/dnsmichi/manubulon-snmp.git /usr/lib/nagios/plugins/manubulon
RUN wget "https://exchange.nagios.org/components/com_mtree/attachment.php?link_id=3121&cf_id=29" -O /usr/lib/nagios/plugins/check_by_snmp && chmod -v 0755 /usr/lib/nagios/plugins/check_by_snmp
RUN ln -sv /usr/lib/nagios/plugins/manubulon/plugins/*.pl /usr/local/bin
RUN ln -sv /usr/lib/nagios/plugins/check_snmp /usr/local/bin
RUN ln -sv /usr/lib/nagios/plugins/check_by_snmp /usr/local/bin
# snmpd vorbereiten und starten
ENV MIBSDIR=/usr/share/snmp/mibs:/usr/share/snmp/mibs/iana:/usr/share/snmp/mibs/ietf:/usr/share/mibs/site:/usr/share/snmp/mibs:/usr/share/mibs/iana:/usr/share/mibs/ietf:/usr/share/mibs/netsnmp
RUN /bin/mkdir -pv /var/run/agentx
CMD /usr/sbin/snmpd -Lo -u Debian-snmp -g Debian-snmp \\
-I -smux,mteTrigger,mteTriggerConf -f
Im Container selbst sind dann die Manubulon Checks sowie check_snmp und check_by_snmp nach /usr/local/bin verlinkt. Zum testen also einfach direkt die Checks aufrufen.
Meine Beispiels snmpd.conf. Mit v2 Community "icinga" sowie einem v3 Benutzer "icinga" und Passwort "abcde%12345".
# # Gehirn-Mag.Net Beispiel snmpd.conf fürs Monitoring # ####################################### # # Allgemeine Einstellungen # # Auf *:161 lauschen agentAddress udp:161 ####################################### # # Auth: 1x SNMPv3, 2x community # # system, interfaces, host, ucdavis, nsExtendObjects view icinga included .1.3.6.1.2.1.1 view icinga included .1.3.6.1.2.1.2 view icinga included .1.3.6.1.2.1.25 view icinga included .1.3.6.1.4.1.2021 view icinga included .1.3.6.1.4.1.8072.1.3.2 # Die folgende Zeile "createuser..." sollte besser in /var/lib/snmp/snmpd.conf stehen # Und das Passwort sollte sinnigerweise angepasst werden ;-) createUser icinga SHA "abcde%12345" AES rouser icinga default -V icinga rocommunity icinga default -V icinga # public darf nur die sysDescr sehen ;-) view public included .1.3.6.1.2.1.1.1.0 rocommunity public default -V public ####################################### # # Build in - ein paar Beispiele # # System Informationen sysLocation GMN-RZ/WDD sysContact Mein.Gehirn-Mag.Net <mein@gehirn-mag.net> sysServices 72 # Process Monitoring proc snmpd # Disk Monitoring disk / 20% includeAllDisks 10% # System Load load 12 10 5 ####################################### # # Erweiterungen # extend check_disk /usr/lib/nagios/plugins/check_disk -w 20% -c 10% extend check_critical /usr/lib/nagios/plugins/check_procs -C gibtesnicht -c 1:
In der dritten Registerkarte direkt über diesem Abschnitt findet sich die von mir verwendete snmpd.conf. Diese kann auch ohne Docker als Ausgangsbasis für eigene Tests verwendet werden.
Zum testen ist noch ein v2 Zugang mit icinga als Community String enthalten, ebenso steht der v3 Zugang direkt in dieser Konfigdatei. Diese sollte aber, wie im Kommentar erwähnt entsprechend in die zweite snmpd Konfig verschoben werden. Die vollständige Doku zur Konfig gibt es hier: http://www.net-snmp.org/docs/man/snmpd.conf.html
Für Checks wie CPU, Plattenplatz usw. verwende ich gerne die SNMP-Checks von Manubulon. Diese sind z.B. in Icinga2 bereits enthalten. Ansonsten finden diese sich hier: http://nagios.manubulon.com/. Leider sind diese nicht mehr aktuell gepflegt, deswegen greife ich gerne auf diesen Fork von einem der Icigna Entwickler zurück: https://github.com/dnsmichi/manubulon-snmp. Diese sind ebenfalls im Container installiert und wären nach /usr/local/bin verlinkt.
Ein paar Beispiele dazu:
root@0b99c3febe7b:/# check_snmp_load.pl -H localhost -2c -C icinga -Tnetsl -w 1,1,1 -c 2,2,1.5 Load (CPUs: 4) : 0.56 1.00 1.34 : OK root@0b99c3febe7b:/# check_snmp_mem.pl -H localhost -2c -C icinga -w 20,20 -c 30,30 Ram : 87%, Swap : 26% : > 30, 30 ; CRITICAL
Das funktioniert schon mal wunderbar 🙂
Um nun "eigene" Nagios-Checks einzufügen muss man lediglich in der Config einen Eintrag der Form "extend <check_name> <check_command mit args>" aufnehmen. In dem Beispiel von mir finden sich folgende zwei Zeilen:
extend check_disk /usr/lib/nagios/plugins/check_disk -w 20% -c 10% extend check_critical /usr/lib/nagios/plugins/check_procs -C gibtesnicht -c 1:
Vom Grundsatz her sieht das zu NRPE ja sehr ähnlich aus. Fehlt noch das passende Gegenstück zu check_nrpe bzw. check_by_ssh. Das gibt es hier: https://exchange.nagios.org/directory/Plugins/%2A-Remote-Check-Tunneling/check_by_snmp--2F-check_snmp_extend--2F-check_snmp_exec/details. In dem Beispiel-Container ist das, wie bereits erwähnt, ebenfalls nach /usr/local/bin verlinkt. Also einfach aufrufen. Und so sehen die beiden Beispiele aufgerufen aus:
root@0b99c3febe7b:/# check_by_snmp -H localhost -2 -C icinga -E check_disk DISK WARNING - free space: / 30394 MB (20% inode=93%);| /=120929MB;127595;143544;0;159494 root@0b99c3febe7b:/# check_by_snmp -H localhost -2 -C icinga -E check_critical PROCS CRITICAL: 0 processes with command name 'gibtesnicht' | procs=0;;1:;0;
Auch das funktioniert super! Mehrzeilige Ausgaben, der richtige Exit-Code: Kommt alles sauber mit rüber.
Das war ja schon mal einiges was man damit tun kann. Es geht aber noch etwas mehr. Ich habe bei den Beispielen mit extend immer einen vollwertigen Nagios-Check aufgerufen. Das darf aber natürlich auch ein ein Skript sein welches zum Beispiel nur einen Integer Wert zurück liefert. Dieser kann dann mit check_snmp abgerufen und entsprechend weiter aufbereitet werden. Die Doku dazu gibt es hier: https://www.monitoring-plugins.org/doc/man/check_snmp.html. Der ist bei vielen Monitoringlösungen bereits mit dabei und ihr ahnt es ja bereits: Innerhalb von Icinga hießt der nur snmp.
Neben der Zugriffskontrolle die man wie so oft natürlich entsprechend umfangreich aufblähen kann ist der Rest der snmpd.conf jedoch eher kurz und übersichtlich gehalten. Also innerhalb kürzester Zeit machbar. Meiner Meinung nach lohnt es sich also SNMP als Alternative zu NRPE und check_by_ssh auf dem Schirm zu haben.

Bei mir kommen regelmäßig Azubis, Praktikanten oder Studenten vorbei. Das ist absolut ok so - man lernt nun mal am Besten die anderen Abteilungen bzw. Unternehmen der Gruppe kennen indem man dort mal ein paar Tage rein schnuppert. Wenn es die Zeit zulässt erzähle ich ganz gerne neben dem was wir so machen noch ein paar Dinge über den üblichen Tellerrand darüber hinaus. Gern genommene Themen sind "Email" (wir haben mehrere TB bei uns auf den Platten liegen), "Webhosting aus Adminsicht mit Hinblick auf Google Pagespeed", "Der Einfluss von langsamen DNS auf ein Firmennetzwerk", "Ethik und Moral zum Thema Monitoring"... Jetzt kommt meistens "langweilig" oder "ne, Ethik ist nicht so meins". Na wunderbar! Das Thema ist gefunden, der Einstieg bereits gemacht 😉
Zuerst einmal gehen wir dann immer der Frage nach was Monitoring überhaupt ist. Grob zusammengefasst findet man dieses hier als Einleitung auf Wikipedia (Logo und Text von hier https://de.wikipedia.org/wiki/Monitoring):

Gehen wir also zunächst mal der Frage nach was man überhaupt so alles mit einem Monitoring-System überwachen kann. Ich frage dann mal nach bzw. lenke die Diskussion in folgende Richtungen:

Vernetzte Dienste
Eine der häufigsten Antworten sind "Dienste" oder die "Verfügbarkeit von Diensten". Das kann sowas einfaches sein wie ein Ping auf Server, Router oder sonstige Geräte. Oder mit etwas mehr Anspruch weil via Protokoll verbunden wird um z.B. nachzusehen ob ein Mailserver artig Hallo sagt, ob ein Webserver eine Webseite ausliefert usw. Das ist ok und richtig so. Nur allzu oft wird hierbei etwas ganz wichtiges übersehen. Kurzer Exkurs: Häufig wird der Dienst alle 5 Minuten geprüft. Im Falle eines Fehlers wird der Abstand verkürzt, oftmals auf zwei Minuten. Bei 3 hintereinander aufgetretenen Fehlern wird alarmiert. Dann mal fix zusammen gerechnet was hier als worst case raus kommt: 9 Minuten. Also nach 9 Minuten wird jemand kontaktiert. Wieder eine offene Frage: Wie wird kontaktiert? Per Email, per SMS? Per Messanger (wie auch immer die heißen mögen)? Wie lange dauert es im Schnitt bis jemand auf die Nachricht reagiert und tatsächlich was tun kann? Und jetzt die einzig spannende Frage zu diesem Bild: Meint Ihr wirklich, dass bei einem produktionskritischen System wo Kunden drauf sind es um die 10 Minuten dauert bis die anrufen um sich zu beschweren, dass Sie nichts mehr arbeiten können? Exkurs Ende. Dienste überwachen ist wichtig. Nur braucht das allzu oft anzutreffende Zeitmodel wie gerade gezeigt eine dringende Überarbeitung. Es ist auf Dauer sehr ungünstig wenn die Kunden das bessere Monitoringsystem sind 😉
Das mit den Diensten muss besser werden. Eine Möglichkeit das zu optimieren ist der Blick auf die Hardware. Was macht die CPU Auslastung? Wie voll ist die Festplatte? Wie steht es um den Arbeitsspeicher? Das sind sinnvolle Ergänzungen die einem helfen ein besseres Verständnis für die Last auf einem System zu bekommen. Und oftmals erhält man hier rechtzeitig Hinweise und kann agieren bevor was ausfällt. Ein Beispiel der von mir gerne verwendeten Hardware-Checks gibt es hier: Monitoring Linux Extended Memory.
Schon wieder Dienste. Die hatten wir doch schon. Ja, zumindest einen Teil. Ich selbst bin riesengroßer Fan davon auch die andere Seite von den Diensten zu betrachten. Beispiel Webserver Apache: Das der Dienst verfügbar ist kann man mittels http bzw. https Anfrage an den Webserver prüfen. Kommt die erhoffte Webseite zurück ist alles gut. Nur was macht der Webserver eigentlich alles? Apache kennt einen Server Status der genau dies verrät. Ein Beispiel wie so etwas aussehen kann? Gibt es hier: https://exchange.icinga.com/dsbits/apache_serverstatus. Oder Du schaust in die angefügte Galerie: Dort sind ebenfalls ein paar Beispiele enthalten. Das habe ich unterm Strich für alles wo etwas mehr Last anliegt bzw. sehr, sehr produktionskritisch ist. Da sind neben dem Beispiel mit apache noch solche Dinge wie ISC DNS, Novell/NetIQ eDirectory, OpenLDAP, NFS-Server, GroupWise, Kopano usw. dabei. Selbst moderne Dateisysteme wie btrfs verraten einem beim genaueren Blick deutlich mehr Details zu ihren internen Vorgängen und Engpässen. Von Routern und Switchen gibt es über die VLANs kaskadierte Sichten zu den Netzwerkports. Netzwerk dicht? Ein Blick aufs Diagramm im Monitoring und sofort ist klar welche VLANs der Auslöser sind. Soviel dazu. Detailschärfe kann im Falles eines Falles das Leben so viel leichter machen. Kombiniert mit sinnvollen Limits und man wird rechtzeitig informiert bevor irgendetwas steht. Angenehmer Seiteneffekt dabei und nochmals am Beispiel apache: Der Server-Status wird ebenfalls via http/https aufgerufen. Also wenn das funktioniert, dann muss der Webserver als solches laufen. Der vorhin angesprochene Check auf http/https kann also weggelassen werden.
Was, schon wieder Dienste? Ja, bzw. ja... Zum Teil kann es lohnend sein Funktionsgruppen zu testen. Ich nenne das jetzt einfach mal so, folgende zwei Beispiele sollen erklären was ich meine: Eine der Basis-Datenbanken für eine große Softwarelösung sei die CRM-Datenbank mit den Adressdaten aller Kunden. Die ist so groß, dass die auf eigenem Blech läuft und sonst nichts macht außer CRM-DB. Über Webservices ist es möglich, dass externe Dritte Änderungen an den CRM-DB Einträgen vornehmen. Wenn es also funktioniert, dass über Webservices ein neuer Dummy-Kunde angelegt werden kann, dann muss auf dem Weg dazwischen alles funktionieren: Firewall, WAF, Webservices, die dortigen Applikationen und zu guter Letzt die CRM-DB selbst. Ein einziger Check, aber unterm Strich eine riesen große Fülle von Dingen die hierbei, wenn auch zum Teil indirekt, geprüft wurden. Geschickte Peformance-Daten hierbei erfasst und schon hat man eine Grundlage für die monatlichen SLA-Berichte an die Kunden. Monitoring kann Spaß machen. Beispiel 2: Eine Email von einem Server aus dem Internet an einen der via DNS gelisteten MX-Server übergeben und kurze Zeit später via IMAP bzw. GroupWare-Konnektor geprüft ob die Mail da ist. Bzw. Eicar-Testvirus (https://de.wikipedia.org/wiki/EICAR-Testdatei) oder GTUBE Spam-Email (https://de.wikipedia.org/wiki/GTUBE) verschickt - die sollten logischerweise nicht da sein oder in der Quarantäne wieder zu finden. So die Art. Weitere Details: Kopfkino. Mach was draus 😉
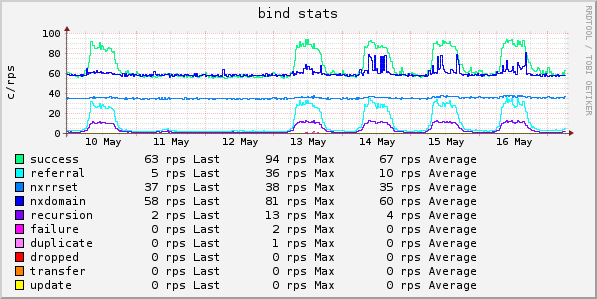
Ein Nameserver mit ein bisschen Grundlast 😉
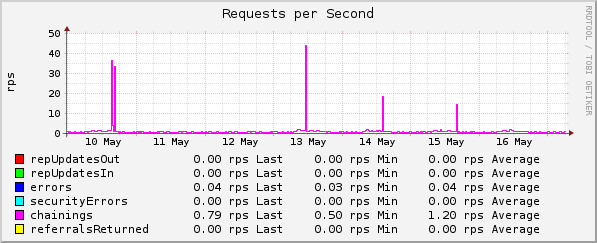
Anfragetypen
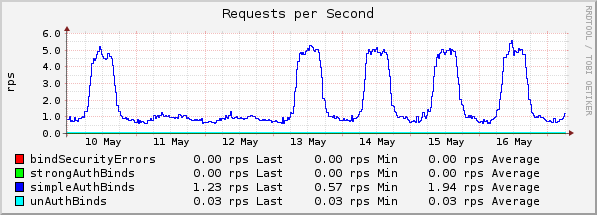
Übersicht Authentifizierungsanfragen

Interne LDAP Operationen
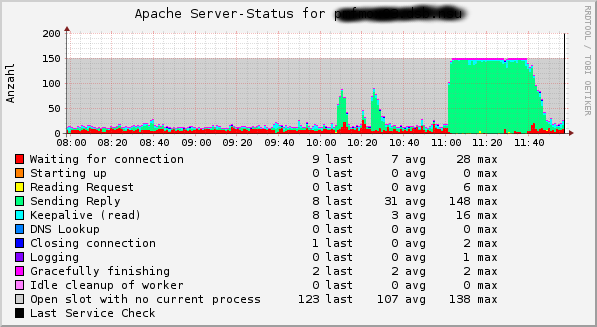
Übersicht über die Apache Prozesse

Übersicht über die apache Prozesse – mit zusätzlichen Anfrageraten

Neben dem bisher gezeigten kann ich noch mit folgenden Beispielen dienen die zum Teil für große Augen sorgen. Einfach mal ein Auflistung einiger Punkte was man so alles machen kann:
Und das waren nur ein paar Beispiele. Alles nur theoretischer Natur? Hab ich so bereits alles in der Praxis zum laufen gebracht - mehrfach zum Teil sogar. Da geht aber noch viel, viel mehr. Und bis jetzt ist das doch alles ok und alles andere als verwerflich. Was soll daran so böse sein wo man sich um Ethik und Moral Gedanken machen müsste? Nun ja, eins hat dies bisher gezeigt: Überwacht werden kann eigentlich so ziemlich alles. Und man kann richtig viel Information daraus gewinnen. Im nächsten Abschnitt gebe ich ein paar Bespiele was man sonst noch so machen könnte - wenn man wirklich wollte.

Da geht doch was 😉

Auf dem Weg ins Glück

Code-Review der anderen Art
Fangen wir mal hiermit an: In vielen mittleren und größeren Unternehmen gibt es Webproxys welche für das Surfen im Internet verwendet werden. Ohne Frage, dass Proxys eine Daseinsberechtigung haben und viele Vorteile mitbringen. Wenn dann auch noch solche Mechanismen wie Single-Sign-On (SSO) dazu kommen wird das richtig super in der Handhabe. Und im Hintergrund noch das Surfverhalten jedes einzelnen Mitarbeiters mit den gängigen Blacklists oder der firmeninternen Whitelist abgeglichen und schon hat man den "surft geschäftlich Quotient" ermittelt. Der ist über Tage hinweg zu tief? Automatische Meldung an den Abteilungsleiter und/oder ins Personalbüro.
Na und bei Email geht das sogar noch einfacher und braucht so zusätzliches Zeug wie SSO doch gar nicht. Die Absender- bzw. die Empfängeradresse ist doch eindeutig. Dazu noch rasch das Unternehmensadressbuch via passender API vom Groupware System abgerufen und abgeglichen. Und Tada: Brauchbare Zahlen über die sich jeder cholerische Personalchef freut!
Bei Dir gibt es eine elektronische Schließanlage? Na wunderbar, schon wieder genug Zahlenfutter welches mit den vereinbarten Arbeitszeiten abgeglichen werden kann.
Das folgende hatten wir mal als Aprilscherz in einer größeren Monitoringumgebung geplant. Auf jedem Arbeitsplatz lief hier Windows. Also via WMI oder Powershell-Remote von jedem Rechner ausgelesen wer angemeldet ist und ob der Bildschirmschoner läuft. Im Monitoring kann dadurch rasch geprüft werden ob es sich lohnt zu einem Kollegen los zu laufen oder ob man doch lieber noch etwas wartet. So in Analogie zur Trojan-Room-Kaffemaschine 😉 Details zu dieser gibt es zum Beispiel hier: https://de.wikipedia.org/wiki/Trojan-Room-Kaffeemaschine.
Das war noch nicht bedenklich genug? Bitte, da geht noch mehr! Aus den Informatonen lässt sich wunderbar eine effektive Arbeitszeit ermitteln. Ja, aber der Kollege könnte doch mal im Meeting sein oder am geschäftlich telefonieren... Und Du denkst das ist ein Problem? Fix im Groupware Terminkalender nachgeschaut ob ein Termin drin steht oder ob laut Telefonanlage der Anschluss gerade besetzt ist.
Apropos Telefonanlage: Du weißt ja, Anlagen zeichnen geführte Gespräche in der Anrufliste auf. Das Unternehmensweite Adressbuch hatten wir ja schon mal im Zusammenhang mit Email. Also fix die Telefonate gegen die Nummern aus dem Adressbuch abgeglichen und schwupp, schon wieder beim privat telefonieren erwischt.
Wer ein Ticketsystem verwendet kann hier zum Beispiel die Anzahl der gelösten Tickets pro Kopf ermitteln. Ok, jeder der darin arbeitet weiß, dass es Tickets gibt die rasch erledigt sind während andere schon mal etwas Hirnschmalz erfordern um gelöst zu werden. Moderne Ticketsysteme kennen aber die Quote der wieder geöffneten Tickets. Ebenso lässt die Anzahl der ausgetauschten Nachrichten je Ticket auf dessen Komplexität schließen. Also wieder eine messbare Eigenschaft über mehrere verknüpfte Werte. Fehlt noch der Bezugswert mit dem dieser Quotient verglichen wird. Da bietet sich zum Beispiel der Abteilungsschnitt an. Das hier keiner behaupten kann die Tickets der Vertriebsabteilung hätten eine andere Komplexität als die der IT-Abteilung. Und genau das ist doch der Punkt und die Lösung steckt bereits in der Behauptung drin: Dann vergleiche doch auf Abteilungsbasis. Oder was auch immer der gemeinsame Nenner bei Dir im Unternehmen ist. Ein paar Male in Folge im Monat als schlechtester Mitarbeiter gekürt oder im Jahresschnitt zu weit hinter den Kollegen zurück? Schon kommt der große Holzhammer vorbei...
Ja und für die Programmierer die sich gerade noch entspannt zurück lehnen: Meint Ihr nicht auch, dass dank Revisionskontrollsystemen sehr elegant ermitteln werden kann wie viel zum Gesamtquellcode von jedem Einzelnen beigetragen wurde? Jaha, aber das ist doch noch keine Aussage über die Qualität des Codes. Manche Zeilen sind viel härter erarbeitet als andere die locker von der Hand gehen. Das mag ja alles sein, aber schon mal was von Quellcode-Bewertungen gehört? So wie z.B. COCOMO? Siehe für allgemeines hier: https://de.wikipedia.org/wiki/COCOMO. Oder gleich noch ein passendes Tool gefällig? Das gibt es hier: https://github.com/boyter/scc. Die Best-Of Liste von unten her gelesen wird dann jeden Monat in der Toilette aufgehängt. Oder wie sagte mein alter Mathelehrer an der Oberstufe immer? "Einmal an der Tafel blamiert fördert die Arbeitsmoral!"
"Diese Abmahnung wurde maschinell erzeugt und benötigt keine Unterschrift." Dabei ging dieser Text doch nur der Frage nach was man denn so alles überwachen kann. Mit ein paar technischen Hinweisen wie man das umsetzen könnte. Hier wird global auf individueller Ebene entschieden ohne Rücksicht darauf ob die erfassten Daten für die gerade im speziellen betrachtete Situation überhaupt vollständig sind. Um im Bild der Zeit zu bleiben wird das Ergebnis per sozialem Netzwerk an der jeweiligen Pinnwand aufgehängt. Unbequeme persönliche Kommunikation mit Konfliktpotential? Wo denkst Du hin? Der Flame War der einem entgeht wäre zu schön gewesen. Als IT-Administrator und vor allem auch als IT-Verantwortlicher sollte man sich die richtigen Fragen stellen. Sei Dir bewusst was Du tust und kenne die Konsequenzen. Bekenne Dich zu dem was wirklich richtig ist. Sei mutig. Sage "nein" wenn es sein muss. Auch oder gerade deswegen im IT-Umfeld. Ethik und Moral.

Nextcloud zeigt einem in der Verwaltung an ob es Updates gibt. Nur mag ich hier nicht immer nachsehen müssen, zumal ich viele Nextcloud-Instanzen zu verwalten habe. Die Logik dahinter müsste man doch für einen Monitoring-Check verwenden können. Alternativen? Bisher habe ich keine gefunden deren Funktionsweise mich überzeugt oder der über einen längeren Zeitraum problemlos funktioniert hätte. Es muss also eine eigene Lösung her!
Ich würde jetzt einfach mal vermuten, dass jeder der diesen Artikel tatsächlich liest Nextcloud kennt. Oder zumindest ownCloud. Sicherheitshalber nochmal nachschauen? Bitte, das geht hier https://nextcloud.com/ bzw. hier https://owncloud.org/. Da ich selbst inzwischen nur noch wenig mit ownCloud zu tun habe und fast alle Installation mit Nextcloud betreibe beziehe ich mich in diesem Blogbeitrag ausschließlich auf Nextcloud.
Wie in einem anderen Blogbeitrag beschrieben mag ich keine Mails welche mich auf verfügbare Updates hinweisen (Statusmails? Nein Danke!). Das wären schlichtweg zu viele Systeme die sich da innerhalb kürzester Zeit melden würden. Ebenso, auch wenn das für eine Plattform reichen täte, bin ich kein Fan davon in Nextcloud nachzusehen. Wenn es für die erste installierte Plattform Updates gibt, dann auch für alle anderen. Unterm Strich viel zu mühsam. Zumal wir auch Kunden haben die Ihre Cloud-Installation selbst betreuen. Hier könnte der Check als Hinweis für den Kunden dienen. Oder für mich als Serverbetreiber Grund genug sein mal wieder den Telefonhörer in die Hand zu nehmen und den Kunden gefühlvoll mit dem notwendigen Nachdruck davon zu überzeugen doch bitte Updates zu installieren. Sicherheit und so. Klappt richtig gut 😉
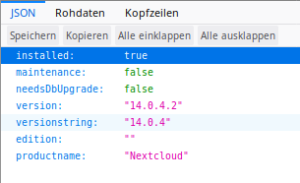
status.php Ausgabe von Nextcloud.
Bleibt die Frage wie prüfen. Ein paar Checks habe ich gefunden welche die lokale Version ermitteln in dem Sie die version.php-Datei im Dateisystem direkt auslesen oder einfach https://<deine.nextcloud>/status.php aufrufen. In diesem JSON-String findet sich die Versionsnummer. Eine aufbereitete Fassung der JSON-Daten siehst Du links im Screenshot. So oder so, der Teil mit der lokalen Versionsnummer ist leicht. Bleibt noch die Frage wie man heraus findet ob es überhaupt Updates gibt. Hierfür habe ich einige verschiedene Ansätze gefunden:
private function getUpdateServerResponse() {
$this->silentLog('[info] getUpdateServerResponse()');
$updaterServer = $this->getConfigOption('updater.server.url');
if($updaterServer === null) {
// FIXME: used deployed URL
$updaterServer = 'https://updates.nextcloud.org/updater_server/';
}
$this->silentLog('[info] updaterServer: ' . $updaterServer);
$releaseChannel = $this->getCurrentReleaseChannel();
$this->silentLog('[info] releaseChannel: ' . $releaseChannel);
$this->silentLog('[info] internal version: ' . $this->getConfigOption('version'));
$updateURL = $updaterServer . '?version='. str_replace('.', 'x', $this->getConfigOption('version')) .'xxx'.$releaseChannel.'xx'.urlencode($this->buildTime).'x'.PHP_MAJOR_VERSION.'x'.PHP_MINOR_VERSION.'x'.PHP_RELEASE_VERSION;
$this->silentLog('[info] updateURL: ' . $updateURL);
// Download update response
$curl = curl_init();
curl_setopt_array($curl, [
CURLOPT_RETURNTRANSFER => 1,
CURLOPT_URL => $updateURL,
CURLOPT_USERAGENT => 'Nextcloud Updater',
]);
In Zeile 7 ist der Update-Server angegeben und in Zeile 15 findet sich der Aufbau der URL. Einige dieser Bestandteile finden sich in der bereits angesprochenen version.php, der Rest sind Versionsnummern der lokal verwendeten PHP-Installation. Dies wird mit reichlich "x" getrennt zu einer langen URL zusammen gesetzt welche z.B. so aussieht:
Diese Adresse geöffnet ergibt folgende Antwort:
<?xml version="1.0" encoding="UTF-8"?> <nextcloud> <version>15.0.0.10</version> <versionstring>Nextcloud 15.0.0</versionstring> <url>https://download.nextcloud.com/server/releases/nextcloud-15.0.0.zip</url> <web>https://docs.nextcloud.com/server/15/admin_manual/maintenance/upgrade.html</web> <changes>https://updates.nextcloud.com/changelog_server/?version=15.0.0</changes> <autoupdater>1</autoupdater> <eol>0</eol> <signature>c4llfwhYTKaEiTWVivJ1NgTIS5q2mxJVJkyew0nd/setTzpXt2H9zXKGQLmjUcy7 fSeW5+wkUfGD2J3XrcLKifGZMjxrhtAW97L1g/o8gp84ZO1WbrOKfneTLDXWkmwg nztf/5z0F0nppOyUX6HR84UhwDbhET7U8JV/1Ik7OO6D361U4sxELUhvg6GyQbdS oJ/t4MvMe1Fs+F5Q7dZzczivxu5oB0n2cVu9WMh8VnV6MiYcKV4/w7poibHMO16k 4IHl6E2hTF3un0obMKy7SRY4xXJ0Ohmj5Ne/8iDRjM7oop5Tzpnf1nPLEJJOZPSN fq4UospVzAmRe4UGPTUiqQ==</signature> </nextcloud>
In diesem Beispiel ist die Version 15.0.0.10 als aktuellere Version zur angefragten 14.0.4.2 verfügbar. Falls keine xml-Datei ausgeliefert wird ist die Nextcloud Installation auf aktuellem Stand.
Das war es mit dem Verfahren zur Prüfung ob es Updates gibt. Bleibt noch die Umsetzung über. Obwohl dies sehr einfach in PHP selbst zu realisieren wäre ist bei mir die Wahl auf Python3 gefallen. Ich wollte schon längst mal wieder was in Python machen um meine angestaubten Python-Kenntnisse aufzufrischen und vor allem zu vertiefen. Also wurde die Sprache der Wahl die aktuelle Version von Python3. Die versions.php ist eine relativ einfach PHP-Datei welche sich gut auslesen lassen sollte. Fehlen noch die benötigten PHP-Versionsnummern. Ein an dieser Stelle gern genommener Trick ist in der vermeintlichen anderen Sprache die benötigten Daten in ein Array zu packen und dieses per JSON auszugeben. Die so umgewandelten Daten lassen sich dann super weiterverarbeiten:
ncVersion = json.loads(subprocess.check_output([
args.php, '-r',
'include \'' + args.file + '\';' + '''
$g = array();
foreach($GLOBALS as $key => $val) {
if(preg_match('/^OC_/', $key)) {
$g[$key] = $val;
}
}
echo json_encode(
array(
'pv' => PHP_VERSION,
'pmav' => PHP_MAJOR_VERSION,
'pmiv' => PHP_MINOR_VERSION,
'prv' => PHP_RELEASE_VERSION,
'g' => $g
)
);
'''
]))
Noch ein kleiner Tipp für alle die PHP an der Stelle nicht so gut kennen: Man könnte einfach das Array $GLOBALS ausgeben, da wären alle Werte drin. Nur gibt es in $GLOABLS eine Referenz auf sich selbst da ja auch $GLOBALS eine globale Variable ist. Und an genau der Stelle steigt json_encode() aus da diese Funktion mit Referenzen nicht umgehen kann. In der versions.php fangen aber alle interessanten Variablen mit "OC_" an und lassen sich somit super filtern ;-).
Den kompletten Check, eine Makro gestützte Beispiel-Konfig für Icinga2 sowie eine kurze Anleitung findet Ihr in meinem GitLab-Account: https://gitlab.com/Gehirn-Mag.net/icinga-and-nagios-plugins/. Bis jetzt liegt da nur der Nextcloud-Update-Check drin, weitere werden aber folgen.
Und so sieht das dann im icingaweb2 aus:
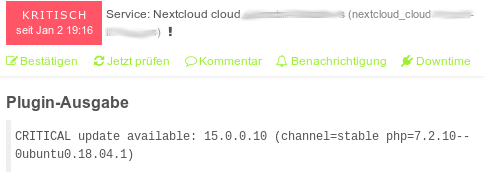
check_nextcloud.py Ausgabe in icingaweb2
Was jetzt noch fehlt ist die Prüfung der Addons auf Aktualität. Auch hierfür sollte sich der passende Anfragestring irgendwo im Quellcode von Nextcloud finden lassen. Mir reicht jedoch vorerst die Prüfung von Nextcloud selbst. Ich bin also vorerst zufrieden. Wer weiß, ggf. reiche ich in ein paar Wochen die Erweiterung für die Addons nach.
Viel Spaß beim benutzen. Feedback und Anregungen gerne via Mail oder hier in den Kommentaren hinterlassen.
An dieser Stelle sind alle Dinge gesammelt die sich seit der Erstellung des Checks und des obigen Beitrages geändert haben. Sollte es zu viel werden wird dieser Beitrag als veraltet markiert und ein neuer verfasst. Bis dahin gilt diese Übersicht.
Es ist möglich den Update Channel in Nextcloud zu ändern. Diese Einstellung findet sich jedoch nicht in der versions.php sondern in der config/config.php. Sollte dort der Channel definiert sein wird dieser verwendet, ansonsten der aus der versions.php. Das hat jedoch zur Folge, dass via -c jetzt noch zusätzlich die config.php mit angegeben werden muss.
Anmerkung zur Icinga Config: Die config.php darf vermutlich vom Benutzer welcher Icinga ausführt nicht gelesen werden. Deswegen ist im CheckCommand ein Aufruf von sudo mit enthalten.
Bei Python Versionen bis 3.5.x erscheint die Fehlermeldung "CRITICAL Cannot parse file /var/www/nextcloud/version.php". Ab Version 3.6 ist dieses Problem behoben.
Falls kein Update auf Pyhton 3.6.x möglich ist kann der Check wie folgt angepasst werden:
// Die import Liste um chardet erweitern - muss ggf. vorher noch installiert werden
import chardet
// Den ersten try: Block wie folgt bearbeiten
try:
jsonResponse = subprocess.check_output([
args.php, '-r',
'include \'' + args.file + '\';include \'' + args.config + '\';' + '''
$g = array();
foreach($GLOBALS as $key => $val) {
if(preg_match('/^(OC_|CONFIG$)/', $key)) {
$g[$key] = $val;
}
}
echo json_encode(
array(
'pv' => PHP_VERSION,
'pmav' => PHP_MAJOR_VERSION,
'pmiv' => PHP_MINOR_VERSION,
'prv' => PHP_RELEASE_VERSION,
'g' => $g
)
);
'''
])
print(jsonResponse)
ncVersion = json.loads(jsonResponse.decode(chardet.detect(jsonResponse)['encoding']))

Ich mag keine Emails. Also in so manchen Momenten zumindest. Ein Beispiel: Ein von mir verwaltetes Emailsystem umfasst mehrere Server die in sogenannte Postoffices unterteilt sind. Das tägliche Backup eines jeden Postoffices generierte bei erfolgreichem Backup eine Email mit einem ausführlichen Bericht und schickte diese an das Sammelpostfach der Systemadministratoren. Soweit so gut, könnte man meinen.
Dennoch gibt es zwei Dinge an diesem Konstrukt die mich grandios stören:
Da muss eine Lösung her, das kann so nicht blieben. Es sind viel zu viele Emails die täglich in das Admin-Postfach eintrudeln - kaum möglich diese wirklich alle mit der notwendigen Sorgfalt zu erfassen. Zumal man auch noch andere Dinge zu tun hat außer Emails auf Vollständigkeit zu prüfen. Und dann gibt es da noch dieses Gerät namens Telefon. Ein jeder Admin weiß was das bedeutet...
Dabei ist die Lösung so einfach: Ein System in das jeder Admin mehrfach unterm Tag rein schaut. Gibt es zumindest bei uns. Monitoring heißt das Zauberwort. Freundlicherweise liefert das oben beschriebene Backup wenn man in der Doku sucht doch tatsächlich das passende Plugin bereits mit. Jetzt weiß das Monitoring ob die letzte Sicherung aktuell genug ist. Und falls nicht ist im Monitoring auch gleich noch der Link zum Protokoll vom Backup-Server hinterlegt. Besser kann es kaum werden. Und angenehm ist es auch:
Diese oder ähnliche Situationen begegnen mir regelmäßig bei der Arbeit. Irgendwelche genau genommen dumpfsinnigen Emails werden durch die Gegend geschickt die im Grundrauschen der Emailflut im Admin-Postfach viel zu schnell übersehen werden. Die Dienstqualität leidet durch das zu späte oder gar nicht richtige Erfassen von aufkommenden Problemen.
An dieser Stelle bin ich Befürworter der Grundthese, dass im Adminpostfach nur die notwendigsten Dinge ankommen sollten. Laufzeitberichte, Diagnosemails usw. gehören ins Monitoring. Dort sind diese viel besser aufgehoben und können bei Problemen kann ganz anders wahrgenommen und bearbeitet werden.
Die Grundidee, dass Monitoring so viel mehr bieten kann wie die nur teils verwendete einfache Dienstüberwachung ziehe ich an vielen Stellen durch: Papierfüllstände und Tonervorrat an die Azubis, Laufzeit-Infos zu Backupjobs an die Kollegen vom Backup, Accountinginformationen der Mailrelays an die Buchhaltung zur monatlichen Rechnungslegung und noch viel, viel mehr Abseits der einfachen Überwachung von ein paar einfachen Serverdiensten... Das kann Monitoring ebenfalls bieten.
Kombiniert mit der rechtzeitigen Erkennung von aufkommenden Problemen bevor Dienste ausfallen und Monitoring beginnt richtig Spaß zu machen. Weitere Blogbeiträge zu diesem Thema werden folgen 😉