


Bei mir kommen regelmäßig Azubis, Praktikanten oder Studenten vorbei. Das ist absolut ok so - man lernt nun mal am Besten die anderen Abteilungen bzw. Unternehmen der Gruppe kennen indem man dort mal ein paar Tage rein schnuppert. Wenn es die Zeit zulässt erzähle ich ganz gerne neben dem was wir so machen noch ein paar Dinge über den üblichen Tellerrand darüber hinaus. Gern genommene Themen sind "Email" (wir haben mehrere TB bei uns auf den Platten liegen), "Webhosting aus Adminsicht mit Hinblick auf Google Pagespeed", "Der Einfluss von langsamen DNS auf ein Firmennetzwerk", "Ethik und Moral zum Thema Monitoring"... Jetzt kommt meistens "langweilig" oder "ne, Ethik ist nicht so meins". Na wunderbar! Das Thema ist gefunden, der Einstieg bereits gemacht 😉
Zuerst einmal gehen wir dann immer der Frage nach was Monitoring überhaupt ist. Grob zusammengefasst findet man dieses hier als Einleitung auf Wikipedia (Logo und Text von hier https://de.wikipedia.org/wiki/Monitoring):

Monitoring Allgemein
Gehen wir also zunächst mal der Frage nach was man überhaupt so alles mit einem Monitoring-System überwachen kann. Ich frage dann mal nach bzw. lenke die Diskussion in folgende Richtungen:
Dienste

Vernetzte Dienste
Eine der häufigsten Antworten sind "Dienste" oder die "Verfügbarkeit von Diensten". Das kann sowas einfaches sein wie ein Ping auf Server, Router oder sonstige Geräte. Oder mit etwas mehr Anspruch weil via Protokoll verbunden wird um z.B. nachzusehen ob ein Mailserver artig Hallo sagt, ob ein Webserver eine Webseite ausliefert usw. Das ist ok und richtig so. Nur allzu oft wird hierbei etwas ganz wichtiges übersehen. Kurzer Exkurs: Häufig wird der Dienst alle 5 Minuten geprüft. Im Falle eines Fehlers wird der Abstand verkürzt, oftmals auf zwei Minuten. Bei 3 hintereinander aufgetretenen Fehlern wird alarmiert. Dann mal fix zusammen gerechnet was hier als worst case raus kommt: 9 Minuten. Also nach 9 Minuten wird jemand kontaktiert. Wieder eine offene Frage: Wie wird kontaktiert? Per Email, per SMS? Per Messanger (wie auch immer die heißen mögen)? Wie lange dauert es im Schnitt bis jemand auf die Nachricht reagiert und tatsächlich was tun kann? Und jetzt die einzig spannende Frage zu diesem Bild: Meint Ihr wirklich, dass bei einem produktionskritischen System wo Kunden drauf sind es um die 10 Minuten dauert bis die anrufen um sich zu beschweren, dass Sie nichts mehr arbeiten können? Exkurs Ende. Dienste überwachen ist wichtig. Nur braucht das allzu oft anzutreffende Zeitmodel wie gerade gezeigt eine dringende Überarbeitung. Es ist auf Dauer sehr ungünstig wenn die Kunden das bessere Monitoringsystem sind 😉
Hardware und Co.
Das mit den Diensten muss besser werden. Eine Möglichkeit das zu optimieren ist der Blick auf die Hardware. Was macht die CPU Auslastung? Wie voll ist die Festplatte? Wie steht es um den Arbeitsspeicher? Das sind sinnvolle Ergänzungen die einem helfen ein besseres Verständnis für die Last auf einem System zu bekommen. Und oftmals erhält man hier rechtzeitig Hinweise und kann agieren bevor was ausfällt. Ein Beispiel der von mir gerne verwendeten Hardware-Checks gibt es hier: Monitoring Linux Extended Memory.
Dienste 2.0
Schon wieder Dienste. Die hatten wir doch schon. Ja, zumindest einen Teil. Ich selbst bin riesengroßer Fan davon auch die andere Seite von den Diensten zu betrachten. Beispiel Webserver Apache: Das der Dienst verfügbar ist kann man mittels http bzw. https Anfrage an den Webserver prüfen. Kommt die erhoffte Webseite zurück ist alles gut. Nur was macht der Webserver eigentlich alles? Apache kennt einen Server Status der genau dies verrät. Ein Beispiel wie so etwas aussehen kann? Gibt es hier: https://exchange.icinga.com/dsbits/apache_serverstatus. Oder Du schaust in die angefügte Galerie: Dort sind ebenfalls ein paar Beispiele enthalten. Das habe ich unterm Strich für alles wo etwas mehr Last anliegt bzw. sehr, sehr produktionskritisch ist. Da sind neben dem Beispiel mit apache noch solche Dinge wie ISC DNS, Novell/NetIQ eDirectory, OpenLDAP, NFS-Server, GroupWise, Kopano usw. dabei. Selbst moderne Dateisysteme wie btrfs verraten einem beim genaueren Blick deutlich mehr Details zu ihren internen Vorgängen und Engpässen. Von Routern und Switchen gibt es über die VLANs kaskadierte Sichten zu den Netzwerkports. Netzwerk dicht? Ein Blick aufs Diagramm im Monitoring und sofort ist klar welche VLANs der Auslöser sind. Soviel dazu. Detailschärfe kann im Falles eines Falles das Leben so viel leichter machen. Kombiniert mit sinnvollen Limits und man wird rechtzeitig informiert bevor irgendetwas steht. Angenehmer Seiteneffekt dabei und nochmals am Beispiel apache: Der Server-Status wird ebenfalls via http/https aufgerufen. Also wenn das funktioniert, dann muss der Webserver als solches laufen. Der vorhin angesprochene Check auf http/https kann also weggelassen werden.
Dienste 2.1
Was, schon wieder Dienste? Ja, bzw. ja... Zum Teil kann es lohnend sein Funktionsgruppen zu testen. Ich nenne das jetzt einfach mal so, folgende zwei Beispiele sollen erklären was ich meine: Eine der Basis-Datenbanken für eine große Softwarelösung sei die CRM-Datenbank mit den Adressdaten aller Kunden. Die ist so groß, dass die auf eigenem Blech läuft und sonst nichts macht außer CRM-DB. Über Webservices ist es möglich, dass externe Dritte Änderungen an den CRM-DB Einträgen vornehmen. Wenn es also funktioniert, dass über Webservices ein neuer Dummy-Kunde angelegt werden kann, dann muss auf dem Weg dazwischen alles funktionieren: Firewall, WAF, Webservices, die dortigen Applikationen und zu guter Letzt die CRM-DB selbst. Ein einziger Check, aber unterm Strich eine riesen große Fülle von Dingen die hierbei, wenn auch zum Teil indirekt, geprüft wurden. Geschickte Peformance-Daten hierbei erfasst und schon hat man eine Grundlage für die monatlichen SLA-Berichte an die Kunden. Monitoring kann Spaß machen. Beispiel 2: Eine Email von einem Server aus dem Internet an einen der via DNS gelisteten MX-Server übergeben und kurze Zeit später via IMAP bzw. GroupWare-Konnektor geprüft ob die Mail da ist. Bzw. Eicar-Testvirus (https://de.wikipedia.org/wiki/EICAR-Testdatei) oder GTUBE Spam-Email (https://de.wikipedia.org/wiki/GTUBE) verschickt - die sollten logischerweise nicht da sein oder in der Quarantäne wieder zu finden. So die Art. Weitere Details: Kopfkino. Mach was draus 😉
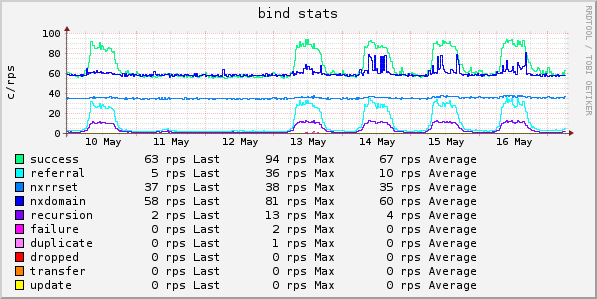
Bind9 DNS
Ein Nameserver mit ein bisschen Grundlast 😉
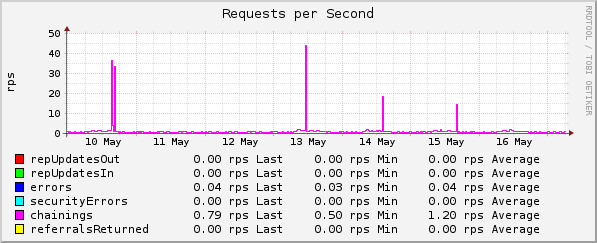
Novell/NetIQ eDirectory
Anfragetypen
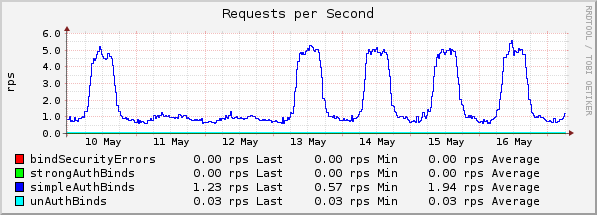
Novell/NetIQ eDirectory
Übersicht Authentifizierungsanfragen

Novell/NetIQ eDirectory
Interne LDAP Operationen
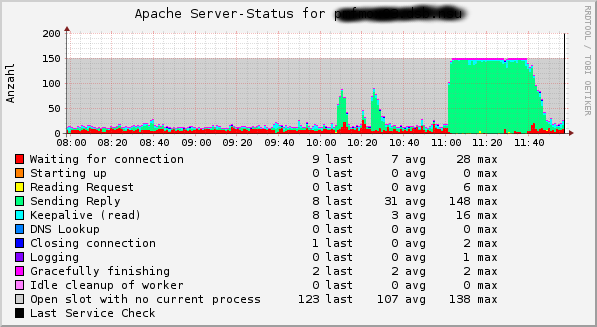
apache2
Übersicht über die Apache Prozesse

apache2
Übersicht über die apache Prozesse – mit zusätzlichen Anfrageraten

Luxus
Neben dem bisher gezeigten kann ich noch mit folgenden Beispielen dienen die zum Teil für große Augen sorgen. Einfach mal ein Auflistung einiger Punkte was man so alles machen kann:
- Für ein Email-Relay welches ausschließlich Emails im Namen von Kunden mit deren Domains versendet: Ein Check welcher prüft, dass die zugehörigen SPF-Records, sofern gesetzt, auch dieses Relay beinhaltet. Natürlich werden die Domains dynamisch ermittelt um bei Änderungen am Adresspool keine Änderung im Monitoring-System zu brauchen.
- Gute Netzwerkdrucker haben die Möglichkeit via SNMP Daten bereits zu stellen. Toner bald leer, Papier aufgebraucht? Im ersten Fall eine Mail an die Materialwirtschaft damit rechtzeitig Nachschub bereit liegt, im zweiten Fall eine Mail an die Azubis den Papiervorrat wieder aufzufüllen. Und bei geleasten Geräten nebenbei die monatlichen Zählerstände an den Dienstleister versendet.
- Via Montioring-API alle https-Webserver ermitteln und den SSL/TLS-Stack zu prüfen. Zum Beispiel hiermit: https://testssl.sh/. Mit geeigneter Monitoringsoftware kann der Link zum Bericht gleich noch bei den Check-Details mit eingefügt werden. Testssl kann dies darüber hinaus auch für SMTP-Server.
- Für Webseitenentwickler ist der Pagespeed sehr wichtig. Warum externe Tools verwenden wenn man doch selbst die Time To First Byte (TTFB) überwachen kann?
- Wir haben genügend Monitoring Checks die überprüfen wie die Hitrate eines Caches ist. Aber mal ehrlich, wer schaut da rein? Die zugehörigen Admins. Warum hier nicht gleichzeitig neben der Hitrate eine Empfehlung berechnen lassen auf welchen Wert man die dazugehörigen Einstellungen setzen müsste? Geheimnis ist das keins, die zugehörigen Formeln stehen oftmals im Handbuch des Servers. Macht das Admin Leben leichter da man nicht jedes mal selbst nach diesen Formeln die passenden Werte berechnen muss. Und dank Laufzeitdiagrammen hat man sogar noch eine Trendübersicht.
Und das waren nur ein paar Beispiele. Alles nur theoretischer Natur? Hab ich so bereits alles in der Praxis zum laufen gebracht - mehrfach zum Teil sogar. Da geht aber noch viel, viel mehr. Und bis jetzt ist das doch alles ok und alles andere als verwerflich. Was soll daran so böse sein wo man sich um Ethik und Moral Gedanken machen müsste? Nun ja, eins hat dies bisher gezeigt: Überwacht werden kann eigentlich so ziemlich alles. Und man kann richtig viel Information daraus gewinnen. Im nächsten Abschnitt gebe ich ein paar Bespiele was man sonst noch so machen könnte - wenn man wirklich wollte.

Die Spezialität nach Art des Hauses
Da geht doch was 😉

Ticketing
Auf dem Weg ins Glück

Matrix
Code-Review der anderen Art
Very special Monitoring
Fangen wir mal hiermit an: In vielen mittleren und größeren Unternehmen gibt es Webproxys welche für das Surfen im Internet verwendet werden. Ohne Frage, dass Proxys eine Daseinsberechtigung haben und viele Vorteile mitbringen. Wenn dann auch noch solche Mechanismen wie Single-Sign-On (SSO) dazu kommen wird das richtig super in der Handhabe. Und im Hintergrund noch das Surfverhalten jedes einzelnen Mitarbeiters mit den gängigen Blacklists oder der firmeninternen Whitelist abgeglichen und schon hat man den "surft geschäftlich Quotient" ermittelt. Der ist über Tage hinweg zu tief? Automatische Meldung an den Abteilungsleiter und/oder ins Personalbüro.
Na und bei Email geht das sogar noch einfacher und braucht so zusätzliches Zeug wie SSO doch gar nicht. Die Absender- bzw. die Empfängeradresse ist doch eindeutig. Dazu noch rasch das Unternehmensadressbuch via passender API vom Groupware System abgerufen und abgeglichen. Und Tada: Brauchbare Zahlen über die sich jeder cholerische Personalchef freut!
Bei Dir gibt es eine elektronische Schließanlage? Na wunderbar, schon wieder genug Zahlenfutter welches mit den vereinbarten Arbeitszeiten abgeglichen werden kann.
Das folgende hatten wir mal als Aprilscherz in einer größeren Monitoringumgebung geplant. Auf jedem Arbeitsplatz lief hier Windows. Also via WMI oder Powershell-Remote von jedem Rechner ausgelesen wer angemeldet ist und ob der Bildschirmschoner läuft. Im Monitoring kann dadurch rasch geprüft werden ob es sich lohnt zu einem Kollegen los zu laufen oder ob man doch lieber noch etwas wartet. So in Analogie zur Trojan-Room-Kaffemaschine 😉 Details zu dieser gibt es zum Beispiel hier: https://de.wikipedia.org/wiki/Trojan-Room-Kaffeemaschine.
Das war noch nicht bedenklich genug? Bitte, da geht noch mehr! Aus den Informatonen lässt sich wunderbar eine effektive Arbeitszeit ermitteln. Ja, aber der Kollege könnte doch mal im Meeting sein oder am geschäftlich telefonieren... Und Du denkst das ist ein Problem? Fix im Groupware Terminkalender nachgeschaut ob ein Termin drin steht oder ob laut Telefonanlage der Anschluss gerade besetzt ist.
Apropos Telefonanlage: Du weißt ja, Anlagen zeichnen geführte Gespräche in der Anrufliste auf. Das Unternehmensweite Adressbuch hatten wir ja schon mal im Zusammenhang mit Email. Also fix die Telefonate gegen die Nummern aus dem Adressbuch abgeglichen und schwupp, schon wieder beim privat telefonieren erwischt.
Wer ein Ticketsystem verwendet kann hier zum Beispiel die Anzahl der gelösten Tickets pro Kopf ermitteln. Ok, jeder der darin arbeitet weiß, dass es Tickets gibt die rasch erledigt sind während andere schon mal etwas Hirnschmalz erfordern um gelöst zu werden. Moderne Ticketsysteme kennen aber die Quote der wieder geöffneten Tickets. Ebenso lässt die Anzahl der ausgetauschten Nachrichten je Ticket auf dessen Komplexität schließen. Also wieder eine messbare Eigenschaft über mehrere verknüpfte Werte. Fehlt noch der Bezugswert mit dem dieser Quotient verglichen wird. Da bietet sich zum Beispiel der Abteilungsschnitt an. Das hier keiner behaupten kann die Tickets der Vertriebsabteilung hätten eine andere Komplexität als die der IT-Abteilung. Und genau das ist doch der Punkt und die Lösung steckt bereits in der Behauptung drin: Dann vergleiche doch auf Abteilungsbasis. Oder was auch immer der gemeinsame Nenner bei Dir im Unternehmen ist. Ein paar Male in Folge im Monat als schlechtester Mitarbeiter gekürt oder im Jahresschnitt zu weit hinter den Kollegen zurück? Schon kommt der große Holzhammer vorbei...
Ja und für die Programmierer die sich gerade noch entspannt zurück lehnen: Meint Ihr nicht auch, dass dank Revisionskontrollsystemen sehr elegant ermitteln werden kann wie viel zum Gesamtquellcode von jedem Einzelnen beigetragen wurde? Jaha, aber das ist doch noch keine Aussage über die Qualität des Codes. Manche Zeilen sind viel härter erarbeitet als andere die locker von der Hand gehen. Das mag ja alles sein, aber schon mal was von Quellcode-Bewertungen gehört? So wie z.B. COCOMO? Siehe für allgemeines hier: https://de.wikipedia.org/wiki/COCOMO. Oder gleich noch ein passendes Tool gefällig? Das gibt es hier: https://github.com/boyter/scc. Die Best-Of Liste von unten her gelesen wird dann jeden Monat in der Toilette aufgehängt. Oder wie sagte mein alter Mathelehrer an der Oberstufe immer? "Einmal an der Tafel blamiert fördert die Arbeitsmoral!"
Fazit
"Diese Abmahnung wurde maschinell erzeugt und benötigt keine Unterschrift." Dabei ging dieser Text doch nur der Frage nach was man denn so alles überwachen kann. Mit ein paar technischen Hinweisen wie man das umsetzen könnte. Hier wird global auf individueller Ebene entschieden ohne Rücksicht darauf ob die erfassten Daten für die gerade im speziellen betrachtete Situation überhaupt vollständig sind. Um im Bild der Zeit zu bleiben wird das Ergebnis per sozialem Netzwerk an der jeweiligen Pinnwand aufgehängt. Unbequeme persönliche Kommunikation mit Konfliktpotential? Wo denkst Du hin? Der Flame War der einem entgeht wäre zu schön gewesen. Als IT-Administrator und vor allem auch als IT-Verantwortlicher sollte man sich die richtigen Fragen stellen. Sei Dir bewusst was Du tust und kenne die Konsequenzen. Bekenne Dich zu dem was wirklich richtig ist. Sei mutig. Sage "nein" wenn es sein muss. Auch oder gerade deswegen im IT-Umfeld. Ethik und Moral.