
von Steffen | Mai 3, 2026 | apache, Tips und Tricks
Ich nutze im ioBroker als Wetter Adapter Weather Undergound. Damit rasch das eigene Wetter abgefragt und in vis-2 mit Material-Design als HTML-Ausgabe dargestellt. Einfach, schlicht - tut es mir. Nur beziehe ich die Icons direkt von Weather Underground. Das muss doch auch anders gehen: Also hab ich mal eben einen apache2 Proxy davorgesetzt. Damit sind meine Zugriffe lokal und zusätzlich noch mit einem Cache. Es lohnt ja nicht jedes Bild immer und immer wieder zu laden - wenn man es doch in einem Cache ablegen könnte.
Bevor einer fragt: Ja, das ist sicherlich nicht sicher einfach so alles ohne irgendwelche Sicherheitsmaßnahmen umzusetzen. Das weiß ich auch. Zum einen läuft das bei mir nur intern und nicht öffentlich im Internet, zum anderen ging es mir um die Funktion. Ich wollte das einfach mal mit apache2 umgesetzt haben. Nicht mehr, nicht weniger 😉 Und betrachte dies als Beispiel: Bei mir war die Ausgangslage ioBroker. Wer weiß, was es bei Dir ist 😛
Das hier will ich haben:

Das aktuelle Wetter inklusive Vorhersage 😉
Und so ist es gelöst - einfach folgenden HTML-Code in einem "Vis 2 Material-Widgets HTML-Vorlage" einfügen:
<style>
.grid-container {
display: grid;
grid-template-columns: 64px auto;
gap: 5px;
padding: 5px;
font-size: 0.8em;
}
.grid-container div {
margin: auto 0;
}
.grid-container img {
width: 64px;
height: 64px;
}
</style>
<div class="grid-container">
<div>
<img src="{v:weatherunderground.0.forecast.0d.iconURL;alt:0_userdata.0.Wetter.Tagesvorhersage.VorhersageIcon;v?v:alt}">
</div>
<div>
<span style="font-weight:bold;">Jetzt</span><br>
{weatherunderground.0.forecast.current.temp} °C
</div>
<div>
<img src="{v:weatherunderground.0.forecast.0d.iconURL;alt:0_userdata.0.Wetter.Tagesvorhersage.VorhersageIcon;v?v:alt}">
</div>
<div>
<span style="font-weight:bold;">Heute: {weatherunderground.0.forecast.0d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.0d.tempMin}
-
{weatherunderground.0.forecast.0d.tempMax} °C
({weatherunderground.0.forecast.0d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.0d.precipitationChance} % ({weatherunderground.0.forecast.0d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.0d.state}
</div>
<div>
<img src="{weatherunderground.0.forecast.1d.iconURL}">
</div>
<div>
<span style="font-weight:bold;">{weatherunderground.0.forecast.1d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.1d.tempMin}
-
{weatherunderground.0.forecast.1d.tempMax} °C
({weatherunderground.0.forecast.1d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.1d.precipitationChance} % ({weatherunderground.0.forecast.1d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.1d.state}
</div>
<div>
<img src="{weatherunderground.0.forecast.2d.iconURL}">
</div>
<div>
<span style="font-weight:bold;">{weatherunderground.0.forecast.2d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.2d.tempMin}
-
{weatherunderground.0.forecast.2d.tempMax} °C
({weatherunderground.0.forecast.2d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.2d.precipitationChance} % ({weatherunderground.0.forecast.2d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.2d.state}
</div>
<div>
<img src="{weatherunderground.0.forecast.3d.iconURL}">
</div>
<div>
<span style="font-weight:bold;">{weatherunderground.0.forecast.3d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.3d.tempMin}
-
{weatherunderground.0.forecast.3d.tempMax} °C
({weatherunderground.0.forecast.3d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.3d.precipitationChance} % ({weatherunderground.0.forecast.3d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.3d.state}
</div>
<div>
<img src="{weatherunderground.0.forecast.4d.iconURL}">
</div>
<div>
<span style="font-weight:bold;">{weatherunderground.0.forecast.4d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.4d.tempMin}
-
{weatherunderground.0.forecast.4d.tempMax} °C
({weatherunderground.0.forecast.4d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.4d.precipitationChance} % ({weatherunderground.0.forecast.4d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.4d.state}
</div>
<div>
<img src="{weatherunderground.0.forecast.5d.iconURL}">
</div>
<div>
<span style="font-weight:bold;">{weatherunderground.0.forecast.5d.date;date(DD.MM.YYYY)}</span>
<br>
{weatherunderground.0.forecast.5d.tempMin}
-
{weatherunderground.0.forecast.5d.tempMax} °C
({weatherunderground.0.forecast.5d.cloudCover} % Wolkendichte)
<br>
Regen: {weatherunderground.0.forecast.5d.precipitationChance} % ({weatherunderground.0.forecast.5d.precipitationAllDay} mm)
<br>
{weatherunderground.0.forecast.5d.state}
</div>
</div>
Im Objekt {weatherunderground.0.forecast.0d.iconURL} stehen URLs wie diese hier: https://www.wunderground.com/static/i/c/v4/28.svg. Und ich hätte gerne, dass daraus das hier wird: https://10.96.100.66:8082/proxy.0/img/https://www.wunderground.com/static/i/c/v4/28.svg. Damit vis-2 keinen externen Apache direkt aufruft, nutze ich den Proxy-Adapter. In diesem ist folgender Pfad gesetzt: aus /proxy.0/img/... mache https://10.96.100.66:4444/img/... wie in folgendem Screenshot gezeigt:
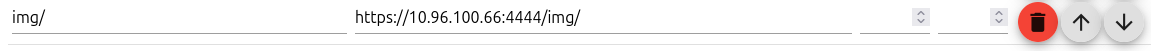
ioBroker Proxy-Adapter Pfad-Einstellung
So wie ich vis-2 in meinem Webbrowser öffne und mir die Wettervorhersage anschaue, werden im Webbrowser die Bilder über die gleiche Adresse geladen, wie vis-2 selbst. Im Hintergrund setzt der Proxy-Adapter, wie oben gezeigt, die Anfragen auf den lokal installieren apache2 um - welcher die Proxy Anfragen an Port 4444 annimmt.
Dazu habe ich in der apache2 Konfig einen neuen vhost angelegt. Dieser lauscht auf Port 4444 und ist via https erreichbar. Als Cache nutze ich das apache2 Modul cache_disk. Damit das korrekt funktioniert, lasse ich die eventuell von der eigentlichen Anfrage gelieferten Header zum Caching durch meine eigenen überschreiben. Als nächstes wird die URL umgeschrieben. Aus https://<meine ioBroker>:4444/img/<https://das eigentliche Bild> soll einfach der Teil nach /img/ extrahiert und als eigentliche Bild-Quelle verwendet werden. Hier gibt es lediglich einen kleinen Haken: apache2 ersetzt // bei https:// durch einen /. Es wird aus der URL also http:/<wohin auch immer>. Deswegen wird die neue URL aus dem Protokoll, verbunden durch einen / und der eigentlichen Anfrage, zusammengesetzt. Sollte es zu einem Fehler kommen, lasse ich ein fallback.svg anzeigen. Und zuletzt lasse ich noch in die Standardlogdaten entsprechende Hinweise eintragen.
So sieht das ganze aus:
Listen 4444
<VirtualHost *:4444>
ServerName imgprx.gehirn-mag.net.internal
SSLEngine on
SSLCertificateFile /etc/apache2/ssl/fullchain.pem
SSLCertificateKeyFile /etc/apache2/ssl/key.pem
# --- Caching ---
Header unset Cache-Control
Header unset Pragma
Header set Cache-Control "public, max-age=86400"
CacheQuickHandler off
CacheLock on
CacheLockPath /tmp/mod_cache-lock
CacheIgnoreHeaders Set-Cookie Cache-Control Pragma Expires
CacheRoot /var/cache/apache2/mod_cache_disk
CacheEnable disk /
CacheDisable /fallback.svg
CacheDefaultExpire 604800
CacheMaxExpire 604800
# --- URL Rewrite für /img/<https://asfasfdsa> ---
# Apache macht aus https://bla... https:/bla... <-- Split in zwei Teile
SSLProxyEngine On
RewriteEngine On
RewriteRule ^/img/(https?:)(.+)$ - [E=TARGET:$1/$2,E=TPROTO:$1,E=TURL:$2]
RewriteCond %{ENV:TARGET} !=""
RewriteRule ^(.*)$ %{ENV:TARGET} [P,L]
# --- Fallback bei Fehlern ---
ProxyErrorOverride On
ErrorDocument 404 /fallback.svg
ErrorDocument 500 /fallback.svg
ErrorDocument 502 /fallback.svg
ErrorDocument 503 /fallback.svg
ErrorDocument 504 /fallback.svg
Alias /fallback.svg /var/www/vhosts/proxy/fallback.svg
# --- Log ---
CustomLog /var/log/apache2/other_vhosts_access.log "%h %l %u %t \"%r\" %>s %b \"cache:%{cache-status}e\" \"target:%{TARGET}e\""
ErrorLog /var/log/apache2/error.log
</VirtualHost>
Im HTML-Vorlage Widget vom ioBroker habe ich die URLs nun wie folgen geändert: <img src="/proxy.0/img/{weatherunderground.0.forecast.1d.iconURL}">. Also lediglich ein /proxy.0/img vorangestellt. Bekommen habe ich also, dass im Webbrowser die externen Bilder ebenfalls über vis-2 geladen werden. Allerdings geht im Hintergrund ein apache2 ran, welcher die gewünschten Bilder aus dem Internet im Sinne eines Proxys lädt und diese sogar noch in einem Cache ablegt.
Und, nochmals erwähnt: Das läuft bei mir nur intern. Letztendlich lädt dieser Proxy alles aus dem Netz, was hinter /img/ steht. Sollte man das also wirklich ungeschützt ins Internet packen wollen, dann wären noch diverse weitere Einstellungen zum Thema Sicherheit sehr sinnvoll. Für meine Zwecke, wo ich im ersten Schritt nur wissen wollte, ob und wie man so etwas in apache2 lösen kann, tut es das mehr wie Dicke. Ich weiß, dass es geht - denn ich habe eine lauffähige Konfig 😀

von Steffen | Nov. 9, 2025 | Netzwerk
Besuch ist da. Und wer kennt es nicht, die Frage nach dem Internet. Egal ob zu Hause der Besuch der Kinder, auf der Arbeit der Gast. Anstatt die Daten mühselig einzugeben: Wie ist eigentlich so ein WLAN QR-Code aufgebaut?
Gemäß RFCs folgen URLs dem üblichen Schema. Das für WLAN wäre somit wifi://<ssid>. Falls man noch einen Benutzernamen und Passwort braucht: wifi://<benutzer>:<passwort>@<ssid>. Nichts Ungewöhnliches, alles so wie man es kennt. Allerdings benötigt man für QR Codes das "ältere" Schema. Diese URL beginnt mit WIFI:, einzelne Schlüssel-Wertpaare werden mit ; getrennt und endet immer mit ;;. Die folgende Tabelle zeigt die möglichen Schlüssel-Wertpaare. Nicht benötigte Schlüssel kann man einfach weglassen.
| S |
Die zu benutzende SSID |
| T |
Typ. Einer der Werte WEP, WPA oder nopass |
| P |
Das Passwort. Falls T:nopass gesetzt ist, wird dieser Wert ignoriert |
| H |
Hidden. Muss auf true gesetzt werden, sofern ein verborgenes Netz verbunden werden soll. Ebenfalls ist false möglich oder eben weglassen. |
Ein paar Beispiele:
WIFI:S:Nur eine SSID;;WIFI:S:MeinWLAN;T:WPA;P:meinPasswort;;WIFI:S:MeinHiddenWLAN;H:true;;
Nachdem man die URL hat, muss man diese noch in einen QR-Code konvertieren. Natürlich gibt es genügend fertige Demos online, mein Ansatz ist jedoch das Selbermachen. Unter Linux verwende ich sehr gerne die libqrencode mit ihrem Befehlszeilentool qrencode. Hierfür gibt es sicherlich mehr als genug Alternativen, ebenso passende Lösungen für Windows oder Mac.
Ein direkte Ausgabe in der Konsole zum sofort scannen würde wie folgt aussehen:
qrencode -tANSI 'WIFI:S:Mein offenes WLAN;;'
-t definiert den Typ, zum Beispiel ANSI für die Konsole. Für Grafikformate kann man zum Beispiel png oder svg angeben. Und mit -o kann man die Ausgabe in eine Datei umlenken. Das sieht zum Beispiel wie folgt aus:
qrencode -tsvg -o/tmp/wifi.svg 'WIFI:S:Mein offenes WLAN;;'
Weitere Details finden sich, wie immer, in der man page.

von Steffen | Nov. 30, 2024 | Allgemein, Tips und Tricks
Mein IO-Broker soll mir Texte senden können - per Signal. Allerdings wollte ich keinen Adapter verwenden, bei dem ich in Abhängigkeit eines Dritten bin. Es musste also eine alternative Lösung her.
Zusammengefasst sollen einfache Textnachrichten per Signal versendet werden. Ich brauche dafür auch keine eigene Telefonnummer, ich verlinke die Instanz gegen meine eigene Nummer. Dass meine Waschmaschine fertig ist, darf gerne als Notiz an mich selbst ankommen. Mich interessiert die Nachricht, nicht von wem diese stammt.
Wenn Cloud-basierte Dienste in der Lage sind Signal-Nachrichten zu versenden, dann müsste das mein lokales System doch ebenfalls können. Gefunden habe ich bei meiner Suche ein kleines Projekt auf GitHub, welches genau dies ermöglicht: https://github.com/AsamK/signal-cli. Also genau das, was ich suchte um von der Kommandozeile aus Nachrichten zu versenden.
Mein IO-Broker läuft auf Ubuntu 24.04. Sinngemäß funktioniert diese Anleitung auch für andere Systeme sowie einer Raspberry Pi basierten Lösung oder was auch immer. Zusammengefasst: Irgendeine Linux-Anwendung soll Nachrichten per Signal versenden. In dem Fall, oder bei den kommenden Ubuntu-Versionen, müssen die entsprechenden Versionsnummern der eingesetzten Software geändert werden.
Im ersten Schritt wird die benötigte Software installiert. signal-cli installiere ich unter /opt - behalte aber die Versionsnummer im Pfad bei. /opt/signal-cli wird dann als Symlink auf die jeweils aktuelle Version gesetzt. Damit kann man bei Updates ohne Probleme zur aktuellen oder wieder zurück zur Vorgängerversion springen. signal-cli benötigt ein installiertes Java. Um einen QR-Code für die Verbindung zwischen Signal auf dem Smartphone und meinem IO-Broker zu erzeugen, wird an der CLI ein QR-Code erstellt und angezeigt. Dafür ist qrencode notwenig.
# Zum Benutzer iobroker wechseln
sudo -u iobroker bash
# Signal darüber informieren, sich zu verbinden
signal-cli link -n iobroker > /tmp/signal.txt &
# Kurz warten und den QR-Code erstellen
qrencode -t ANSI `cat /tmp/signal.txt`
# Natürlich sollte hier das jeweils aktuelle Release von der GitHub Seite ausgewählt werden ;-)
wget https://github.com/AsamK/signal-cli/releases/download/v0.13.9/signal-cli-0.13.9.tar.gz
# entpacken ...
tar xvfz signal-cli-0.13.9.tar.gz
# ... und nach /opt verschieben. Wie erklärt noch den SymLink setzen.
mv signal-cli-0.13.9 /opt/
ln -sv signal-cli-0.13.9/ signal-cli
# Falls noch nicht vorhanden: Java installieren
apt install openjdk-21-jre
# Und gleich noch qrencdoe
apt install qrencode
Nun kommt der eigentliche interessante Teil: signal-cli muss initial einmalig auf mein Signal verbunden werden. Da IO-Broker Nachrichten versenden können soll, wechsle ich im ersten Schritt per sudo zum Benutzer iobroker.
Hierbei wird via signal-cli der Link-Vorgang initiiert. Dies muss gestartet werden und läuft im Hintergrund weiter. Für den Fall, dass man zu langsam ist und die Sitzung beendet wird, beginnt man einfach nochmals von vorne. Sobald der Link-Vorgan im Hintergrund läuft, kann man den QR-Code erstellen. Damit dieser korrekt dargestellt wird, sollte die Konsole entsprechend groß genug sein. Sobald man den QR-Code hat wechselt man zum Smartphone, startet Signal und wählt Einstellungen/Gekoppelte Geräte/Neues Gerät und folgt den Anweisungen. Signal ist nun verbunden, in der Liste der vertrauten Geräte erscheint der IO-Broker.
Eine erste Testnachricht wird wie folgt verschickt:
date | ./signal-cli -u +49177....24 send --notify-self --message-from-stdin +49177....24
Die Nummer ist natürlich gegen die eigene Handynummer zu tauschen. Es sollte eine Notiz an einen selbst ankommen.
Um aus IO-Broker heraus einfacher Nachrichten versenden zu können, habe ich den obigen Befehl in ein kurzes Shell-Skript gepackt. Auch hier ist die eigene Nummer entsprechend anzupassen.
#!/bin/sh
# Ein einfaches Hilfsskript um per Signal-Nachrichten zu versenden
NO="+49177....14"
cat | /opt/signal-cli/bin/signal-cli -u $NO send --notify-self --message-from-stdin $NO
Dieses Skript habe ich unter /usr/local/bin/signal-send abgelegt. Zeit, das Ganze im IO-Broker zu integrieren. Dafür habe ich ein einfaches Blockly-Skript erstellt. Die Variable Message dient hier nur als Platzhalter und kann natürlich um beliebige Objekte erweitert oder ausgetauscht werden.
Fertig
Die Testnachricht kam an, alles funktioniert wie es soll. Mein IO-Broker teilt mir nun das ein oder andere wichtige Ereignis via Signal mit: Die Waschmaschine im Keller, welche fertig ist und noch viele weitere, spannende Dinge.

von Steffen | Juli 6, 2024 | Allgemein, PV
Ich habe eine Photovoltaikanlage mit einem Batteriespeicher von BYD. Die funktioniert und tut soweit, was sie soll. Nur beim Update stellt diese sich gerne quer.
Es gibt, meines Wissens nach, 3 Varianten eine BYD-Batteriebox mit einem Update zu beglücken:
- Die Be Connect App fürs Smartphone. Die gibt es im Android als auch Apple App-Store.
- Die Be Connect Anwendung für Windows:
- Per WLAN direkt auf die BYD-Box verbunden
- Per LAN auf die BYD-Box verbunden
Mit WLAN habe ich das Problem, dass sowohl mein Android als auch iPad sich zwar mit dem BYD-WLAN verbinden, diese Verbindung allerdings sehr rasch wieder trennen: Hinter der BYD-Batterie gibt es kein Internet. Deswegen bevorzuge ich inzwischen die Variante übers heimische LAN.
Variante 1: Be Connect App
Suche im Appstore Deines Smartphones/Tables nach der Be Connect App von BYD. Sobald Du diese gefunden und installiert hast, startest Du diese einfach. Im lokalen LAN kannst Du nun das letzte Update herunterladen. Im nächsten Schritt trennst Du Deine WLAN-Verbindung und verbindest Dich auf ein WLAN mit dem Namen BYD-????. Hierbei sind ???? 4 Ziffern welche bei mir auf einem Aufkleber seitlich in dem kleinen Kasten mit der Sicherung ist. Das Passwort fürs WLAN lautet BYDB-Box.
Variante 2: Be Connect unter Windows
Du lädst die Be Connect Anwendung für Windows auf Dein Windows aus dem Internet. Sobald Du diese startest kannst Du, analog zu Variante 1, über den Update-Knopf das letzte Update herunterladen. Trenne nun Dein WLAN und verbinde Dich auf Deine Batterie. Der Rest ist analog zur Variante 1.
Und hier fangen meine Probleme an: Ich verliere regelmäßig, wie oben geschrieben, die Verbindung zum BYD WLAN. Oder aber, das BYD WLAN steht erst gar nicht zur Verfügung.
Bei letzterem hilft es die Batterie zu stoppen und neu zu starten (aus- und wieder einschalten). Nach kurzer Wartezeit ist das WLAN nun verfügbar.
Das erste Problem habe ich für mich dahingehend erledigt, dass ich nun per LAN direkt auf meine BYD-Box zugreife - auch ohne WLAN. Mein Windows Notebook darf sehr wohl mit dem WLAN verbunden sein - die BYD-Box kann auch über ihr Netzwerkkabel angesprochen werden.
Variante 3: Per heimischen LAN
Im ersten Schritt suche ich die IP-Adresse der Batterie-Box. Das kann ich zum Beispiel auf meinem Internet-Router erledigen. Sobald ich die IP ermittelt habe, kann ich diese zum Beispiel im Webbrowser eingeben: Es erscheint eine Anmeldemaske für die ich allerdings keine Zugangsdaten habe.
Wie in einem der Screenshots zu sehen ist, hat die Batterie bei mir die Adresse 10.96.101.34. Lasse Dich von der 10-punkt-irgendwas nicht stören. Bei vielen anderen lautet die IP meist 192.168. und irgendwelche weiteren, zwei Zahlen.
Als nächstes gehe ich auf den Startknopf und gebe
cmd
ein. Allerdings starte ich diese Anwendung nicht sofort, sondern wähle "als Administrator ausführen". Nun gebe ich folgende Befehle ein:
route add 192.168.16.0 mask 255.255.255.0 10.96.101.34
Austauschen musst Du lediglich die 10.96.101.34. Hier gehört die IP Deiner BYD-Box in Deinem Netzwerk rein. Alternativ zu Windows selbst, kann man diese Route in vielen Internet-Routern direkt eintragen. Dann würde sie jedem Gerät im Netz automatisch zur Verfügung stehen und nicht nur dem aktuell verwendeten Windows-System.
In folgendem Screenshot ist das ganze gezeigt. Hat man alles richtig gemacht, antwortet die 192.168.16.254 auf ping Anfragen.
Der Download ist ein Zip-Archiv. Entpackt findet man einiges an Daten. Im markierten Ordner liegt die Dokumentation zur Software.
Die Software selbst findet sich unter BCP_....exe - die zweite Markierung im Screenshot. Diese ist kein Setup, kann also direkt gestartet werden.
Beim Login wählt man "Installer" und als Passwort "BYDB-Box".
Im ersten Schritt muss man auf den "Connect" Knopf drücken. Ist die Verbindung erfolgreich, kann man mit klick auf "Refresh" die Anzeigen aktualisieren.
Es ist durchaus lohnenswert sich die ganzen Zahlen und Daten etwas näher anzuschauen. Das Windows-Programm liefert viel mehr Daten als die SmartPhone App.
Mit Klick auf Updates kann man zunächst die aktuellen Updates herunterladen. Die auf der Batterie aktuellen Versionen werden angezeigt, ebenso die verfügbaren Updates. Sollte man diese installieren wollen, klickt man auf Update. Während BMS einigermaßen zügig vorangeht, braucht BMS nach erreichen der 100% noch ca. 20 Minuten. Einfach warten und die Software neu starten. Die BMS-Versionsnummer sollte sich geändert haben (Infos hierzu siehe auch in der Doku welche ebenfalls im ZIP-Archiv enthalten ist).
Ich mag die Variante per LAN. Keine Probleme mit WLAN, die Windows-Anwendung zeigt viel mehr Details an als die SmartPhone App. Und während Updates laufen, kann ich weiterhin mein heimisches WLAN/LAN verwenden.

von Steffen | Juni 4, 2024 | Nextcloud, Tips und Tricks
Eine nette, kleine Aufgabe: Ziehe ein Nextcloud-System von einem Webserver auf einen anderen um. Klingt zu einfach - der Haken an der Geschichte war rasch gefunden: Nextcloud "alt" ist Version 24, aktuell ist die Version 29. Somit "alt" PHP 7.4, "neu" PHP 8.3. Auf dem alten System kann man nicht updaten, da das PHP zu alt und keine ausreichend neue Version vorhanden ist - auf dem neuen System kann man kein altes Nextcloud installieren, da das PHP dort zu neu und kein ausreichend altes PHP vorhanden ist. Dann halt ganz anders.
Achtung: ein sauberes Update von Nextcloud wird, gemäß Dokumentation, immer von einer auf die nächste Hauptversion gemacht. Also zuerst die aktuell laufende Version auf den letzten Patchstand gehoben, dann der Wechsel der Hauptversion. Also 24.x aktualisieren, dann der Wechsel auf 25. 25.x aktualisieren, dann der Wechsel auf 26. Und dies macht man so lange, bis man bei der aktuellsten Version angekommen ist.
Den Weg wollte ich allerdings nicht gehen - die Quelldistribution war mit RHEL 7 mindestens genauso alt wie Nextcloud 24, somit kam ein Update auf Ubuntu 24.04. Egal welche Distribution: die alte Umgebung hat ein altes PHP, die neue ein neues. Und irgendwie sind die nur bedingt kompatibel zueinander. Also hätte ich im ersten Schritt ein Ubuntu nehmen können, welches ebenfalls PHP 7.4 anbietet. Das grundlegend einrichten, Nextcloud 24 darauf migrieren. Solange Nextcloud Updates machen wie Nextcloud das zulässt. Sobald das Ende erreicht ist, kann man das Ubuntu auf das nächste Release heben. Mit dem nun aktuelleren PHP kann man Nextcloud weiter updaten. Bis auch hier nichts mehr geht, da das PHP zu alt ist. Also wieder Ubuntu auf die nächste Variante bringen und das Spiel nochmals von vorn.
Das wäre "sauber". Und wäre auch konsequenterweise richtig, wenn am Quellsystem regelmäßig Updates eingespielt worden wären. Dem war aber nicht so, ich bin derjenige der es korrigieren darf. Der obige Weg dauert mir zu lange, deswegen habe ich eine alternative Lösung gesucht.
Nextcloud ist eines der Systeme, welches nach einem Update erkennt, dass die Datenbank eine Aktualisierung braucht. Gegebenenfalls darf man via CLI und occ Befehl noch ein paar Indizies einfügen oder die ein oder andere Anpassung vornehmen. Das war es. Und an genau der Stelle setze ich an:
- Ich installiere auf dem neuen Server ein aktuelles, leeres Nextcloud. Grundlegende Dinge richte ich bereits ein, allerdings nur das allernötigste. Die meisten Einstellungen werden durch die Übernahme der Daten aus dem Altsystem eh überschrieben. Du bist unsicher, was man bereits jetzt tun kann oder nicht? Dann warte bis zum Schluss.
- Nun lösche ich die Datenbank und lege eine neue, aber leere Datenbank an.
- Vom alten System kopiere ich die Datenbank auf den neuen Server.
- Ebenso kopiere ich vom data Verzeichnis die Verzeichnisse der Benutzer. Achtung: Nicht alles, sondern wirklich nur dass, was ein Benutzer ist. Solche Dinge wie die Update-Daten sollte man wirklich überspringen.
- Und nun beginnt die Magie: Es gibt Fälle, da ging der folgende Schritt per WebUI schief. Deswegen lieber die Kommandozeile verwenden. Sobald die Installation etwas größer wird, macht dies eh mehr Sinn. Also an die CLI gewechselt und occ upgrade aufgerufen. Nextcloud entdeckt, dass die Datenbankversion zu alt ist und beginnt deswegen mit den notwendigen Aktualisierungen.
- Im nächsten Schritt meldete ich mich an der WebUI an. Ein grober Blick über die sichtbaren Daten sowie die Benutzer sollte jetzt bereits wieder erfolgreich sein.
- Als Nächstes habe unter Administrationseinstellungen/Verwaltung/Übersicht die Sicherheits- und Einrichtungswarnungen angeschaut und entsprechend alles umgesetzt.
- Hat das alte System Apps, die noch fehlen? Oder das neue, ein paar zu viel davon? Jetzt ist eine gute Gelegenheit.
- Neue Systeme kennen neue Einstellungen. Mal alles auf Plausibilität prüfen - ob das so noch alles heute passt wie damals erdacht.
- Testen, testen, testen …
- Fertig
Das System läuft und ist zudem auf den aktuellsten Stand. Damit das so bleibt, kann man zum Beispiel folgenden Beitrag noch umsetzen: https://gehirn-mag.net/nextcloud-auto-update-via-cli/
Das Kopieren der Daten braucht halt die Zeit, die das Kopieren der Daten nun mal braucht. Allerdings habe ich mir die Update-Orgie erspart. Mal wieder die Welt eines Kunden gerettet, dieser ist glücklich. Mal schauen, welche Herausforderung mich als nächstes erwartet.

von Steffen | März 30, 2024 | Firewall, IPv6, Linux, Netzwerk, OPNsense, Tips und Tricks
Eigentlich ist es zu verlockend: Neben einer einzigen IPv4-Adresse weist mir mein Internetprovider auch gleich noch eine IPv6-Adresse zu. Doch halt: Ist das wirklich nur eine einzelne IP-Adresse? Eben nicht, man bekommt einen Netzwerkblock zugewiesen. Ich könnte also jedem einzelnen Rechner, sogar jedem einzelnen Dienst in meinem Heimnetzwerk eine eigene IPv6-Adresse zuweisen. Das eröffnet ungeahnte Möglichkeiten - Es ist Zeit das mal auszuprobieren!
In meiner Umgebung steht eine OPNsense Firewall welche sich ums Internet kümmert. Mein Testserver, welcher von extern erreichbar sein soll, ist ein Ubuntu basiertes System welches sich bei mir in einem Netzwerk mit dem Namen PREP befindet. Der Name ist eigentlich egal, für dieses Beispiel sinniger wäre vermutlich der Begriff DMZ. Als Internetanschluss besitze ich Glasfaser (FTTH), das Prinzip hier gilt jedoch sinngemäß genauso für ADSL. Sogar für statische IP-Adressen ist dieses Beispiel sinngemäß anzuwenden.
Noch eine kurze Anmerkung: Unter IPv6 ist das fehleranfällige NAT für solche Aufgaben unerwünscht. Jeder sollte genügend IPv6 Adressen erhalten, um alle internen Systeme via IPv6 erreichbar zu machen - sofern man möchte. Da man genügend öffentliche IP-Adresse hat, ist kein NAT notwendig.
OPNsense
Meine OPNsense ist via Dualstack am Internet verbunden, d.h. ich habe neben meiner IPv4 noch eine IPv6 Adresse mit einem /56er Präfix anliegen. Obwohl ich Glasfaser habe, ist es vom Verfahren her so wie hier in der Dokumentation von OPNsense beschrieben für DSL. Das macht keinen Unterschied. Hier der Link zur Doku: https://docs.opnsense.org/manual/how-tos/ipv6_dsl.html. Schreibe mir einen Kommentar oder eine Nachricht, falls hierzu weitere Details erwünscht sind.
Meine IPv4 Adresse für dieses Netzwerk ist manuell gesetzt. Für IPv6 ist Track Interface eingetragen. Das zu verfolgende Interface ist WAN, als Prefix-ID verwende ich df (223 dezimal = df hexadezimal).
Sollte ich von meinem Internetprovider als Prefix 2001:0db8:1234:5600/56 erhalten, so beginnen alle IPv6 Adressen in meinem PREP Netzwerk mit dem Prefix 2001:0db8:1234:56df/64. Die letzten zwei Stellen, welche bisher als 00 dargestellt waren, werden durch die gesetzte Prefix-ID ersetzt. Hierbei handelt es sich um zwei hexadezimale Ziffern mit je 4 Bit. Eine hexadezimale Ziffer kennt 16 verschiedene Möglichkeiten von 0 bis f. Das sind 2⁴ = 16 Möglichkeiten. Zwei hexadezimale Ziffern sind somit 8 Bit. Mein Prefix wird also von /56 zu /64 "verlängert". Das ist auch genauso gewollt, dass man mehrere Netze mit IPv6 Adressen bestücken kann - deswegen bekomme ich von meinem Provider ein /56er Prefix.
Linux
Als Linux verwende ich ein Ubuntu basiertes System. Letztendlich ist egal welches Linux zum Einsatz kommt. Die gezeigten Verfahren sollten bei den gängigsten Distributionen sinngemäß übertragbar sein.
Wie im Screenshot gezeigt, hat mein Ubuntu als IPv6-Adresse unter anderem die 2a00:79c0:72b:2edf::2000/128 erhalten. Das ist ein Beispiel einer Adresse, welche tatsächlich bei mir mal vergeben war. Allerdings nur bis zum nächsten Tag, da wählt sich mein System neu ein und bekommt eine andere IP-Adresse. Zusammengefasst: Diese Adresse ist gültig, allerdings wird dort sicherlich kein System mehr erreichbar sein 😉
Diese IP täte bereits reichen und kann entsprechend verwendet werden. Das Linux-System bekommt bei jedem Neustart erneut diese Adresse zugewiesen. Der Trick ist ziemlich einfach: Unter OPNsense die Seite Services/ISC DHCPv6/Leases öffnen und man findet folgenden Eintrag:
Unter Ubuntu ist es ebenfalls möglich eine eigene Adresse zu setzen, in dem man einen passenden Token definiert. Dieser Token wird einfach an das Prefix angefügt. In diesem Beispiel verwende ich hierfür diesen: 0000:0000:cafe:0001. Abgekürzt wird dies als ::cafe:0001 dargestellt. Dafür wird in der /etc/netplan/00-installer-config.yaml folgende Zeile ergänzt:
network:
ethernets:
ens34:
dhcp4: true
ipv6-address-token: "::cafe:0001"
version: 2
Dies ist eine weitere Möglichkeit eine "statische" IP zu erhalten, trotz wechselndem Prefix. Mittels "netplan apply" wird der Eintrag aktiviert.
Nochmals zusammengefasst: Das PREP Netzwerk erhält von OPNsense ein IPv6 Prefix welches in diesem Beispiel um df erweitert wurde um auf 64 Bit zu kommen. Die ersten 56 Bit sind dynamisch und ändern sich bei jeder Einwahl erneut. Die letzten 64 Bit können selbst vergeben werden. Wie oben gezeigt entweder per DHCPv6 oder per ipv6-address-token. Funktionieren tun beide Varianten.
Statische oder dynamische IPv6-Adresse
Sollte man, wie ich ein wechselndes IPv6 Prefix haben, sollte man die IP-Adresse über einen der gängigen DynDNS-Dienste erreichbar machen. Einfach dessen Anleitung befolgen, wie man einen IPv6 Eintrag anlegt. Hat man ein statisches Prefix, kann man den Eintrag direkt in der DNS-Verwaltung vornehmen.
OPNsense Alias
Nun benötigt man in der OPNsense Firewall noch eine Regel, welche übers WAN-Interface den Zugriff auf den Server erlaubt. In diesem Beispiel habe ich ein Apache auf dem Ubuntu installiert, welcher lediglich an Port 80 für http ran geht.
In der OPNsense verwende ich für interne Adressen ganz gerne Aliase. Hat man eine statische IP-Adresse, ist dieser rasch angelegt. Allerdings habe ich ein wechselndes Prefix. Hierfür hat OPNsense allerdings die passende Lösung parat: Ein Alias vom Typ "Dynamic IPv6 Host". Ich lege also unter Firewall/Aliase einen neuen Alias an, trage einen Namen ein, wählte den erwähnten Typ und setze als Content den Token welcher ebenfalls unter Ubuntu eingetragen wurde: ::cafe:0001 - oder gekürzt als ::cafe:1 dargestellt. Selbstverständlich funktioniert das ebenso für das oben gezeigte ::2000. Als Interface, damit OPNsense das passende Prefix wählt, gebe ich noch mein PREP Netzwerk an.

Funktionskontrolle gefällig? Hierzu unter Firewall/Diagnostic/Aliases wechseln und den neu angelegten Aliase auswählen. In der Liste der IP-Adressen steht bei mir der folgende Eintrag: 2a00:79c0:72b:2edf::cafe:1. Zu Beginn ist das Prefix welches ich von meinem Internetprovider erhalten habe, die Prefix-ID des PREP Interfaces ist df und als Token ist ::cafe:1 hinterlegt. Sobald sich OPNsense neu mit dem Internet verbindet, werden die ersten 56 Bit der Adresse automatisch angepasst.
Firewall Regel
Die Regel für die Firewall ist nun rasch erledigt. Auf dem WAN-Interface eingehend für IPv6, Quelle any und als Ziel der neu angelegte Alias eingetragen. Das war es.

Funktionstest und Fazit
Zum Schluss ein kurzer Funktionstest: Der DNS-Aufruf zeigt die richtige IPv6-Adresse an, ein einfacher Aufruf via curl zeigt die Ausgabe vom Webserver an. Alternativ kann das natürlich ebenso mit einem Webbrowser geöffnet werden - falls man die Konsole nicht mag.
Wie gezeigt, ist es mit OPNsense rasch erledigt einen Homeserver via IPv6 im Internet erreichbar zu machen. Da man genügend öffentliche IPs erhält, kann man jeden Dienst mit einer eigenen IP ausstatten. Und, das angewendete Schema, kann man durchaus auf andere Systeme übertragen: Es muss kein Linux-Server sein, hier geht jedes andere IPv6 fähige Betriebssystem, welches den passenden Dienst anbietet. Ebenso kann OPNsense auf Firewall- bzw. Router-Seite durch alternativen ersetzt werden - solange diese mit wechselnden IPv6 Prefixen umgehen können.

von Steffen | Juni 14, 2023 | DNS, Gestern war alles besser, Netzwerk, Seltene Wunder
... und das ist ziemlich dumm. Oder doch nicht? Mal wieder Freitag, ein DynDNS2-Protokoll kompatibler Update Client behauptet, er kann die Antwort vom Server nicht verstehen. Es ist also eine gute Zeit, um sich das mal näher anzusehen.
Ok, DynDNS usw. ist genau genommen egal: Letztendlich ist das eine API die via http bzw. https auf irgendeinen Webserver bzw. Webservice zugreift. Die Daten zur Anfrage werden klassischerweise als GET oder POST übermittelt, die Antwort kommt als irgendein ASCII-Text zurück. Reiner Text, XML, JSON - so irgendwas. Unterm Strich: Das ist eine Anfrage an eine Web-API. Reicht für den Moment, kann also auch weit jenseits von DNS-Servern und wechselnden IP-Adressen passieren.
So, und was passiert denn hier jetzt? Der Client behauptet er versteht die Antwort vom Webserver nicht. Per tcpdump oder wireshark einen trace erstellt erhält man den unten gezeigten Screenshot. Das funktioniert übrigends super da DynDNS2 tatsächlich noch http verwendet. Auch wenn viele Implementationen inzwischen https ebenso können - aber halt nun mal nicht alle. Und das ursprüngliche Protokoll war auf "http" festgelegt.

Im Screenshot ist ein Testanfrage. Mit "nohost" als Antwort ist die zwar in einen Fehler gelaufen, macht aber nichts. Deutlich sichtbar ist eine 6 in der Zeile davor, genauso wie eine 0 in der Zeile danach. Der DynDNS-Client erwartet aber direkt "nohost" und keine Zahl. Also ja, nachvollziehbar.
Wobei, das ganze mal in einem normalen Webbrowser geöffnet und mit F12 in die Entwicklertools gewechselt ergibt Folgendes:

Ok, das ist jetzt kein "nohost" Fehler sondern eine "nochg" Statusmeldung. Aber egal, der gleiche Server nur ein anderer Client der angefragt hat: Beim Webbrowser fehlen die Zahlen. Richtig spannend: Ein tcpdump von dieser Anfrage: Die Zahlen sind da. Zusammengefasst: Der Webbrowser kommt mit diesen Zahlen zurecht, er schneidet sie heraus bzw. hat sie, wie auch immer, verarbeitet. Der Automat welcher die API kontaktiert hingegen nicht. Seltsam. Oder doch nicht?
Nein, eigentlich nicht. Das ist ein normales Verhalten bei http. Doch der Reihe nach. Da steht als Webserver Apache und dies stimmt auch. Hier passiert folgendes: Wenn man das mod_deflate aktiviert kann der Webserver Inhalte vorm Übertragen komprimieren. Das spart Übertragungsbandbreite, geht allerdings auf CPU-Kosten. Da die letzten Jahre verhältnismäßig gesehen die CPUs immer leistungsfähiger geworden sind gegenüber der verfügbaren Internetbandbreite: Eine leichte Rechnung. Nächster Einschub: Ein Webserver übermittelt im Kopf die Größe der Daten welche er übermittelt. Bei statischen Daten wie zum Beispiel einer ISO-Datei: Einfach im Dateisystem nachgeschaut wie groß die Datei ist und gut. Der Webbrowser dankt es, in dem er beim Download anzeigt, wie viel er bereits übertragen hat. In Relation zur Zeit ergibt das die Downloadgeschwindigkeit, in Relation zu der Datengröße den bereits erreichten Fortschritt in Prozent. Daraus ableiten kann man nun noch die geschätzte Zeit bis zur Fertigstellung des Downloads.
Wie ist das aber bei Inhalten, die dynamisch zur Laufzeit erstellt werden? Da weiß man doch gar nicht, wie groß die letztendlich sind. Den Fall kennt sicherlich auch jeder: Der Browser weiß, wie viel er bereits heruntergeladen hat, nur weiß er nicht wie viel noch kommt und somit auch nicht wie lange dies wohl dauern wird. Wozu die ganze Erklärung? Da der Webserver nicht weiß wie groß die Daten werden hat er als Transfer-Encoding "chunked" gewählt. Also sehr frei übersetzt "gestückelt". Als Trenner in Einzelteile nimmt ein Webserver ein ganz einfaches Maß: Er überträgt Textdaten, also betrachtet er das zeilenweise. Die Zeile "nohost" aus dem Screenshot oben ist nun mal 6 Zeichen lang. Danach folgt noch eine leere Zeile und die ist, oh Wunder, 0 Zeichen lang. Der Webbrowser versteht natürlich chunked encoding und bereitet die Daten bevor er sie anzeigt richtig auf. Ein tcpdump hingegen zeigt die blanken Daten wie sie soeben eben übertragen wurden. Für beide Ansichten gilt somit: Richtig, aus dem jeweiligen Betrachtungswinkel heraus.
Und wie löst man das Ganze? mod_deflate im Apache abschalten? Nein, will man nicht unbedingt. Gibt viele Gründe warum man den behalten sollte. Es gibt allerdings noch einen anderen Weg: chunked encoding kam mit http/1.1, bei http/1.0 gab es das noch nicht. Also folgenden Eintrag in die Apache-Konfig für die API-Datei: "SetEnv downgrade-1.0". Die Direktive macht genau das was sie einem suggeriert: Egal mit welcher Variante vom http-Protokoll die Anfrage rein kommt: tue intern so, als wäre es eine http/1.0 Anfrage. Und da es hier noch kein chunked encoding gab ist der Spuk vorbei. Der client, in diesem Falle ddclient, kann wieder fehlerfrei mit seiner API.
Zusammenfassend betrachtet: Ein Einzelfall? Sicherlich nicht. Warum sonst sollte der apache Webserver die Möglichkeit besitzen intern einen Downgrade des anfragenden Protokolls vorzunehmen. Ich kenne in der Tat noch einige weitere Fälle in dem man dieses Vorgehen verwendet. Somit alles gut, der Freitag ist gerettet, das Problem ist gelöst.
Moment, stopp. Wirklich? Mal ernsthaft bitte! Schau nochmals in den Screenshot vom tcpdump rein. Wenn, wie in diesem Falle, der Client nicht mit den Varianten von möglichen http/1.1-Antworten klar kommt und stattdessen http/1.0 benötigt: Warum gibt er dann wie in der ersten Zeile sichtbar als verwendetes Protokoll http/1.1 an? Mit einem http/1.0 hätte es dieses Problem doch nie gegeben. Chunked encoding gibt es erst seit http/1.1. Es ist leider nun mal so, dass das Problem des Clients auf dem Server einfacher zu beheben ist wie an dem Ort wo es tatsächlich passiert: Im Server war es eine einzelne Zeile in der Konfig. Beim Client müsste man auf keine Ahnung wie vielen Installationen entsprechend nachbessern. Daraus resultierend ist die weit verbreite Meinung, dass der Server schuld sein muss, wenn er mit dem Client nicht richtig kommunizieren kann. Das mag ab und zu sicherlich richtig sein, aber nun mal eben nicht immer. Also behebt man als Admin mal wieder die Fehler der Anderen, obwohl man selbst bis dahin alles komplett richtig gemacht hätte. Ein Einzelfall? Sicherlich nicht ...

von Steffen | Mai 17, 2023 | Linux, Netzwerk, Tips und Tricks, Verschlüsselung
Zwei Server an verschiedenen Standorten bei irgendeinem der großen Hosting-Provider: Irgendwie möchte man die sogar verbinden. Nur wie? Eine Lösung ganz ohne VPN, mit SSH.
Zurück zur Ausgangssituation: Zwei Server, direkt im öffentlichen Internet, an zwei verschiedenen Standorten wollen Daten austauschen. Als Beispiel nehmen wir einen MariaDB-Cluster sowie syslog. Maria läuft wie MySQL auf Port 3306/tcp, syslog auf 514/udp. Ok, syslog ginge auch via tcp. Aber syslog Nachrichten per tcp? Nein, wenn es irgendwie anders geht, dann anders. Udp ist für syslog einfach das schönere Protokoll.
Neue Lösungen braucht das Land
Was könnte man also tun? Denkbar wäre eine direkte Verbindung übers Internet. Jeweils eine Firewall auf beiden Systemen und für die Datenbank als auch syslog nur Verbindungen vom jeweils anderen Node annehmen. Dir läuft es gerade bei dem Gedanken daran eiskalt den Rücken herunter? Gut mir auch, also nächster Ansatz.
Also dann doch mit vernünftiger Verschlüsselung. Ein VPN wäre ganz nett. Hm, klar - kann man machen. Da hab ich jetzt allerdings keine Lust drauf. Ein IpSec zwischen zwei einzelnen Rechnern ohne Netzwerk dahinter? Naja... OpenVPN: Keine Lust auf Serverkonfig. WireGuard? Nein, ich will kein VPN. Next!
Aber jetzt: ssh port forwarding. Das ist super, leicht einzurichten und funktioniert. Wobei: ssh jedes mal neustarten wenn der Rechner neustartet? Das geht super via autossh (https://www.harding.motd.ca/autossh/README.txt). Der Vorteil von autossh gegenüber dem Start via systemd: Falls der Tunnel während der Laufzeit abbricht startet ihn autossh einfach neu. Das ist sehr schön. Weniger schön: Port forwarding bei ssh? Das geht nur mit tcp. Das will ich aber gar nicht für syslog haben. Da wäre mir udp lieber. Ihr kennt den Text? Richtig, next!
Ssh und autossh war schon toll. Allerdings kann ssh neben port forwarding auch noch die Möglichkeit des tunnel device forwarding. Dabei entsteht ein Point-to-Point tun-Interface auf beiden Seiten. Schon kann man auf diese virtuelle Netzwerkkarte zugreifen, womit man will. Die eigentlichen Daten werden allerdings, wie gewünscht, per ssh übers Internet übertragen. Für meinen Einsatzzweck ist das mehr wie ausreichend.
Umsetzung
Und wie funktioniert das nun? Einfach das unten angefügte Skript auf beiden Servern installieren und sobald alles fertig ist ausführen. Einer der Server ist "Master", der andere der "Slave". Beide starten zunächst ein tun Interface und richten eine Point-to-Point IP darauf ein. In meinem Beispiel hat der Master die 10.255.255.1, der Slave die 10.255.255.2. Achtung, da point-to-point: Die Maske lautet 255.255.255.255. bzw. /32. Es braucht kein Netz, die einzelnen IPs reichen völlig aus.
Nachdem dies erledigt ist, wird auf dem Master via autossh eine SSH-Verbindung auf den slave eingerichtet mit dem device forwarding welche von autossh kontrolliert wird. In dem Beispiel verwende ich den Benutzer "autossh" welcher auf dem Slave angelegt sein muss. Dieser braucht keine shell oder der gleichen, lediglich ein Home-Verzeichnis in dem in authorized_keys der verwendete public key des masters hinterlegt ist.
Das ganze wurde um folgende Funktion ergänzt: Falls ein ping auf die IP der Gegenseite funktioniert, dann muss man nichts tun. Falls nicht lege ggf. das tun Interface an bzw. setze die grundlegenden Einstellungen erneut. Falls autossh läuft wird dieser Prozess beendet. Irgendwas scheint ja offensichtlich nicht zu funktionieren - sonst hätte der erste ping check geklappt.
#!/bin/bash
#
# Richtet Grundlegend das tun-Interface für den SSH-Tunnel ein.
#
# 2023-05-17, gehirn-mag-net: Init...
# Ein paar Einstellungen
TUNNO=9
TUN=tun$TUNNO
IP=/usr/sbin/ip
IPMASTER=10.255.255.1
IPSLAVE=10.255.255.2
HOSTNAMEMASTER=tglic1
HOSTNAMESALVE=tglic2
PING=/usr/bin/ping
AUTOSSH=/usr/bin/autossh
SSHSLAVE="autossh@123.xxx.yyy.zzz"
# Wer ist wer?
if [ "$HOSTNAME" == "$HOSTNAMEMASTER" ]; then
ROLE="MASTER"
IPADDR=$IPMASTER
IPPEER=$IPSLAVE
else
ROLE="SLAVE"
IPADDR=$IPSLAVE
IPPEER=$IPMASTER
fi
echo "${ROLE}: $IPADDR p2p $IPPEER"
# Solange ping sauber durchläuft muss nichts getan werden
$PING -c1 -W5 $IPPEER
if [ $? == 0 ]; then
echo "Peer erreichbar."
exit 0
fi
# ggf. tun Device anlegen, Adresse zuweisen
echo "Prüfe Device tun${TUNNO}..."
$IP link show dev $TUN &> /dev/null || $IP tuntap add dev $TUN mode tun
$IP addr show dev $TUN | grep "$IPADDR" &> /dev/null || $IP addr add dev $TUN ${IPADDR}/32 peer $IPPEER
$IP link set dev $TUN up
$IP addr show dev $TUN
# AutoSSH starten - sofern Master
if [ "$HOSTNAME" == "$HOSTNAMEMASTER" ]; then
echo "Prüfe AutoSSH..."
# AutoSSH starten - ggf. beenden falls noch aktiv
AUTOSSHPID=$(ps aux | grep ssh | grep " \-w${TUNNO}\:${TUNNO} " | tr -s ' ' | cut -d' ' -f2 | tr '\n' ' ')
if [ -n "$AUTOSSHPID" ]; then
echo "Stopping existing autossh with pid $AUTOSSHPID..."
kill $AUTOSSHPID
fi
echo "Starte autossh..."
$AUTOSSH -f -M 0 \
-o "ServerAliveInterval 60" \
-o "ServerAliveCountMax 3" \
-o "ExitOnForwardFailure yes" \
-N -T -w${TUNNO}:${TUNNO} $SSHSLAVE
ps aux | grep "[a]utossh"
# Fertig
sleep 2
$PING -c1 -W5 $IPPEER
exit 0
fi
# Fertig
echo "Warten auf Gegenseite..."
exit 0
Nun braucht es noch eine kleine Änderung auf dem slave: Folgende Zeile muss in der sshd_config vorhanden sein. Ohne diese würde OpenSSH die Verwendung des tunnel interfaces verbieten. Wer es ganz elegant mag: Per Match auf den autossh-Benutzer auf diesen beschränken.
PermitTunnel yes
Fehlt noch ein automatischer Aufruf des Skriptes beim Systemstart. Das könnte man per systemd erledigen. Allerdings hat mich die Erfahrung gelehrt, dass cron die bessere Alternative ist. Vor allem weil mit cron sehr leicht die regelmäßie Kontrolle realisiert werden kann. Im folgenden Beispiel starte ich alle 15 Minuten das Skript auf beiden Servern erneut. Falls es Probleme geben sollte, würden diese automatisch bereinigt werden.
@reboot /usr/local/sbin/gmn-tun.sh 2>&1 | /usr/bin/logger -t gmn-tun
*/15 * * * * /usr/local/sbin/gmn-tun.sh 2>&1 | /usr/bin/logger -t gmn-tun
Sobald das Skript auf beiden Servern gestartet ist kann der Master mit der IP 10.255.255.1 die 10.255.255.2 erreichen: Den slave. Und umgekehrt. Syslog funktioniert per 514/udp, ebenso kann MariaDB via tcp synchron gehalten werden. Wunderbar 🙂
Fazit
Ist diese Lösung perfekt? Ein VPN mag für die zu übertragenden Daten einen geringeren Resourcen-Verbrauch haben. Dafür muss man ein VPN einrichten. Von daher finde ich diese Lösung über ssh ganz nett. Vor allem, und das war eigentlich das Hauptanliegen dieses Beitrags, zeigt es wieder einmal aufs Neue wie vielseitig ssh sein kann. Vor allem dann, wenn kein VPN installiert ist bzw. installiert werden kann. Ein ssh allerdings vorhanden ist...

von Steffen | Dez. 19, 2022 | Gestern war alles besser, Netzwerk, Seltene Wunder
Neulich führte ich ein Gespräch mit einem Techniker. In hitziger Diskussion über die Performance von Kopiervorgängen von Daten hat er mir folgendes an den Kopf geworfen: „… neulich habe ich die gleiche Datenmenge von 500 GB in 4 Stunden über eine 80 MBit Leitung übertragen…“ (mehr …)

von Steffen | Dez. 8, 2022 | Gestern war alles besser, Netzwerk, Seltene Wunder
„Die Warenwirtschaft meldet Benutzername oder Passwort falsch – das muss am VPN bzw. der Firewall liegen…“ „Aha, Du bist also bereits per VPN verbunden und bekommst von der Anwendung die Meldung, dass es da ein Problem mit den Zugangsdaten gibt? Ja, glasklar, dass muss am VPN liegen. Oder sogar an der Firewall…“
„Ich bekomme keine Emails mehr, die Firewall ist schuld.“ „Gestern ging es noch?“ „Ja, gestern war alles in Ordnung.“ „Habt ihr an der Firewall etwas geändert?“ „Nein“ Auch hier wieder: Glasklar, die Firewall ist schuld. Oder vielleicht doch der Postfachspeicher bei dem sich einfach nur ein Service verheddert hat.
Eins meiner persönlichen Highlights: „Ich bekomme keine Emails mehr, die Firewall ist schuld.“ „Gestern ging es noch?“ „Ja, gestern war alles in Ordnung.“ Meine Erfahrung hat mich gelehrt erstmal eine Testnachricht zu schreiben. „Wie, die kam an? Ja kann es einfach nur sein, dass Dir seit gestern niemand mehr eine Email geschickt hat?“ Ergo: Wer an Einsamkeit leidet, sollte die Firewall kontrollieren. Richtig gemein: Die Emailadresse in einschlägigen Newslettern angemeldet: Das Postfach steht nie wieder still. Helfen kann so viel Freude bereiten.
Zurück zum Thema: „Die Webesite lässt sich nicht öffnen, die Firewall ist schuld.“ So langsam kann ich es nicht mehr hören. „Den Stuttgarter Automobilbauer schreibt man übrigens ohne ‚ä'“ „Ach, wirklich?“ „Ja, und es ist sogar egal welchen von beiden Du meinst…“ Also auch hier: Rechtschreibfehler in der URL? Muss an der Firewall liegen welche arglistig Buchstaben vertauscht.
Nebenbei: Missing Feature in Webbrowsern: Eine Rechtschreibkorrektur für URLs. Kann doch so schwer gar nicht sein. Oder warum ist eigentlich nie besetzt wenn man sich verwählt hat? Ach, ich mag solche Themen. Wir schweifen gerade allerdings ab.
Zurück zur eigentlichen Problematik: Hier kommt das Mensch sein einfach nur voll zum tragen. Sobald irgendetwas anders läuft wie von mir erwartet und ich verstehe die Ursache nicht, dann schiebe ich die Schuld auf das was ich am wenigsten kapiere. Also letztendlich auf das was am weitesten weg von mir ist. Einfaches Prinzip, oder? Und dann wird klar was die Aussage „da geht was nicht, die Firewall ist schuld“ wirklich bedeutet: Den Menschen heute ist gar nicht mehr klar warum man überhaupt eine Firewall braucht. Firewalls sind unbequem und schränken nur ein. Eine any-to-any-allow-Regel ist doch sicher genug? Was soll da schon passieren?
Das ist aber nur die Hälfte der Wahrheit: Wenn ich irgendetwas nicht kapiere und die Schuld auf das, was mir am weitesten entfernt liegt schiebe, dann habe ich doch bereits die erste Hälfte der Problematik nicht verstanden: Mir ist gar nicht mehr klar wie eine Anmeldung an einer Warenwirtschaft funktioniert, ich kenne gar keine Details mehr über den Fluss einer Email, der Rechner weiß doch was ich meine – egal ob ich mich vertippe oder nicht.
Aber hey, da hab ich einen Tipp für Dich – weil es ist doch total leicht und eigentlich absolut simpel: Wenn das, was weit weg von mir ist, eine Firewall ist, dann doch hoffentlich auch von dem mir gegenüber. Wie peinlich wäre es zuzugeben, dass ich mein Passwort 3x falsch eingegeben habe. Wie gut, dass mein gegenüber von der Firewall vermutlich genauso wenig Ahnung hat wie ich. Win-Win für beide Seiten. Wunderbar. Mal wieder die Welt gerettet. Ein hoch auf die Firewall. Ironie Ende.

















